Q&A about KERI
This document is part one. Part two is Q-and-A Security. Both files shares a common Glossary that has:
- an alphabethically ordered list of abbreviations
- an alphabethically ordered list of definitions
The questions are of a varied level: basic and detailed. The answers are mostly directed towards generally interested people and newbies.
*Q = one star question. Novice to KERI, advanced in DIDs
Q = two star question. Proficient in DIDs and advanced in KERI
*Q = three star question. Expert in DIDs and proficient in KERI
Why should you read or step through the Q&A?
To get a different angle to the same topic: KERI.
Critical stance welcomed
Just don't try to rewrite history, nor be lazy
KERI receives three types of scrutiny from domain experts:
- "KERI can't do it"
- "KERI doesn't do something new"
- "DID:XYZ has been designed, KERI needs to explain how it's different"
- Ad 1. When respected colleagues think KERI can't keep up to its promises, we value the well-founded questions and suggestions of domain experts after they thoroughly read the KERI whitepaper. We'll happilly keep explaining KERI because we'd hate it when respected experts misunderstand the design.
- Ad 2. After a while some experts say 'well then KERI doesn't do something new'. That's acceptable for us, because we're able to prove the design history of KERI and that it simply hasn't been done before.
- Ad 3. However, we can't accept having to explain the differences to people who just "invented" something new, something similar to KERI, using the same terms and thereby spreading confusion. Let the newbees benchmark themselves against KERI. We're moving forward with CESR, ACDC, OOBI etc.
May this Q&A be able to help you acquiring deep knowledge about KERI.
We welcome every form of positive contribution and will certainly allow for learning time!
The questions are of a varied level: basic and detailed. The answers are mostly directed towards generally interested people and newbies.
*Q = one star question. Novice to KERI, advanced in DIDs
Q = two star question. Proficient in DIDs and advanced in KERI
*Q = three star question. Expert in DIDs and proficient in KERI
| TBW | means: to be written
| TBW prio 1 | means to be written with the highest priority, 3 = no urgency, 2 = average importance |
Inspired by presentation given and questions asked on the SSI webinar May 2020, but also issues raised and the progress made, here on Github (Turn on 'Watch' if you want to be notified of conversations).
Beware: A Q&A is always work in progress. Tips & help welcome.
Disclaimer
Some of the respondents in the open repo and presentations have been explicitly named as a source, like Samuel M. Smith Ph.D., Charles Cunningham, and Orie Steel. If there is no reference added to the answers, then it's a mixture of sources and edits in the question. Most of the editing is done by @henkvancann, which might have introduced omission, errors, language glitches and such. Sorry for that, feel free to correct by submitting a pull request (PR).
For practical reasons educational images uploaded by Github members have been downloaded. We de-personalised them by giving images a new name. Under these new names these images have been uploaded to github and used in the Q&A to clarify the questions and answers.
KERI's content is licensed under the CC by SA 4.0. license. Parts of the video offered on SSI Meetup webinar 58 have been captured and uploaded to Github to support the answers to general questions about digital identity and more in depth answers to question about KERI.
We've done our best to protect the privacy of Github users by investigating the images we used. We haven't come across personal identifiable information (pii). However, should we have made a mistake after all, please let us know and we'll correct this immediately.
List of questions and definitions
|TBW|
Knowledge you should be confidently applying
- The definitions in the glossary
- Public private key pairs
- Hashing and hashes
- Signatures
- W3C DIDs
Actions you should be comfortable with
- Accrue knowledge and keep existing knowledge up to date
- create a key pair safely and back it up safely
- sweep to a new wallet
Jump table to categories
PART ONE
- General
- Why the internet is broken
- Open source licenses
- KERI and DIDs
- Wallets
- Signatures
- Proofs
- Private Key Management
- Blockchain
- Root of trust
- KERI operational
- Agencies
- Virtual Credentials
PART TWO
- Q&A section KERI security considerations
- KERI operational security
- Identifiers
- Event logs
- Inconsistency and duplicity
- Key rotation
- KEL and KELR
- Witness
- Watchers
- KERI and blockchain settled DIDs
- Security Guarantees
Q&A section General
*Q: What is KERI?
Key Event Receipt Infrastructure; a secure identifier overlay for the internet.
Hmm, a mouthful of terms. Let's start with the identifier. One of the basic (!) forms of KERI identifiers is this example:

***Q: Why is KERI and all its supporting tools so complex?
"Complexity" is relative. Compared to what is KERI and ACDC complex?
Based on the constructive ideas the founder Samuel Smith has developed over time in his career plus the awareness that in the self-sovereign identity field there had been to little attention for security as the most important feature of digital identifiers, KERI had to be build from the ground up.
The main design principles have a designated page "Concepts" but in brief:
- Security first, confidentiality second, privacy third
- Offer a remedy for the broken internet
- Minimal sufficient means
- Use of proven -, seasoned -, but dumb cryptography
This lead to the understanding that KERI in nothing is like something else in the SSI space. It's the Internet identifier Platypus.
Because of this many new concepts and new terms had to be specified, and always thoroughly anchored in relevant scientific resources. A new type of language emerged, not seldom lovingly addressed as a "Sam-ism" (referring to the language used by its founder). According to KERI's objective (and ACDC's follow-up on this in the Verifiable Credentials arena) the [Universal Identity Theory] (.md) could be completed. Hence, KERI's complexity stems from three main aspects of its current nature:
- it's a new concept
- it's different from anything else in the field
- it's all encompassing
There are some reasons why KERI might be perceived as complex where instead it could involve other aspects:
-
KERI is the new kid on the block who undermines reasons for existence of others with a pretty solid case. The KERI team calls this progress and whoever it involves might have to reconsider their tenets. All are invited to merge efforts or contribute to KERI and move forward together. The KERI team wishes to contribute to other projects as soon as it's move forward.
-
People think they could pick some ideas from KERI and then bolt this onto there own developments. This doesn't advance clarity in the field. Moreover, KERI's design principle (3. above) "Minimal sufficient means" causes that the KERI team are very much interested in what somebody think he/she could leave out and still meet all the fundamental objectives;
securityto begin with.
Yes, KERI is perceived as being complex, we won't deny this or look away. We're working as hard as we can to create educational resources, explanatory websites and we will continue to do so. The current (fall 2022) resources listed below.
Resources
Technical Concepts developed by and explained by prof. Samuel M. Smith
Direct links: All relevant white papers and a table of IETF-drafts of which the status is kept up to date.
Explanatory articles from Henk van Cann about KERI, CESR, OOBI, Autonomic identifiers:
- Medium-articles with a bit more sophisticated layout and response options. Medium is a company.
- Markdown alternatives on Github userpage of Henk van Cann
KERI and ACDC for Muggles by Drummond Reed / Sam Smith
Docs about technical concepts behind KERI: Questions and Answers general and focussed on security, Glossary KERI Suite
Explanation of KERI development tools and techniques (preliminary link): KERI development environment
Howto's of WebofTrust documentation effort in github project page: Howto
*Q: How does KERI look like?
This is most probably the form in which you might get to see KERI (just as an example!):
BDKrJxkcR9m5u1xs33F5pxRJP6T7hJEbhpHrUtlDdhh0
<- this the bare bones _identifier_
did:aid:BDKrJxkcR9m5u1xs33F5pxRJP6T7hJEbhpHrUtlDdhh0/path/to/resource?name=secure#really
<- this is _a call to resolve_ the identifier on the web
Currently KERI is just code, that can be tested and executed in a terminal on the command line. Private key management of KERI will look like wallets.
Key Event Logs (KEL) and Key Event Receipt Log (KERL) are files with lots of encrypted stuff in there.\

(@henkvancann)
*Q: How is KERI an overlay?
It does not require the current internet and it's protocols to change, nor Trust over IP (ToIP) system or current blockchains to change. KERI can be added to it and, nevertheless, KERI can function all encompassing.
(henkvancann)
*Q: Why use KERI?
Because there is no secure universal trust layer for the internet, currently (2022).
KEI is both privacy preserving and context-independent extensible. This means KERI is interoperable across areas of application on the internet. It does so securely, with minimal sufficient means.
Sam Smith: KERI essentially repairs internet.
**Q: What problem does KERI specifically solve?
KERI solves the Secure Attribution problem, which means that we can be a 100% sure "who said what" over the internet. KERI does so by the security and authenticity first adagium, signing all key-state-changing events in a hash-chained log file (KEL) and this log is cryptographically verifiable to the root-of-trust.
Additionally in the decentralized identity space KERI solves the portability of Self Sovereign Identifiers. Currently you can't move the identifiers you control from one platform or one infrastructure to another. And that makes your self-sovereign identifiers not truly self sovereign. KERI fixes this too.
*Q: Why would KERI suddenly be a game changer in the decentralized identity field?
Because we've been reconfiguring and rethinking the security guarantees behind decentralized identity systems since 2015. To overcome the lack of portability in the current decentralized identity systems, we've introduced a few new concepts that some people in the decentralized identity ecosystem have trouble to get their head around. Especially the blockchain-oriented part of the community.
*Q: How does KERI match DIDs?
There is a whole section to answer this simple question that has many-sided answers: KERI and DIDs.
**Q: Why do you reinvent blockchains and claim it's something new?
To begin with KERI has no blockchain, and doesn't depend on blockchains. If an implementation of KERI depends on blockchains at all, KERI operates blockchain agnostic.
Secondly, KERI doesn't support a crypto currency. It doesn't need a native currency because it can easily connect to one, if needed. And again, KERI is crypto currency agnostic while doing so.
Lastly, KERI is fundamentally different from blockchains like Ripple (Permissioned PBFT consensus) or Stellar (incomplete open public, non-permissioned PBFT consensus): it doesn't need total ordering, time stamping and Proof of Authority consensus on transactions registered on a ledger.
Blockchain and KERI is comparing apples and oranges. But we're happy to do that exercise for the hard-to-convince part of the SSI community.
KERI, the internet identifier Platypus

KERI is nothing like we already know of. It's a mixtures of things.
You can't say _"Oh, KERI lays eggs, so it must be a reptile"_ It's not a reptile.
And then you go _"I see, but it gives birth, so it must be a mammal"_.
It's also not a mammal. It's KERI.
It may have the characteristics you describe, but it's a species of its own.
(*SamMSmith*)
**Q: How can you get away with not complying to the security model (and guarantees) of an open public blockchain?
KERI better fits the Identity space. Doing away the total ordering in blockchains is a huge performance - and throughput gain, plus less worry about governance. There's also not such a thing as consensus forks. KERI solves (or "gets away with" if you wish) this by a mechanism called duplicity detection. Watchers are all that matter. They guarantee that logs are immutable by one very simple rule: "first seen wins".
There is a separate Q&A Security to answer the extensive list of Security related questions.
***Q: Could we see a WASM module in the near future for Sidetree and DID:peer interoperability?
WASM is certainly on the road map, but for the main issue of Sidetree and did:peer interop, see the core KERI spec repo issue for more info.
(CharlesCunningham)
*Q: How does KERI match the trust-over-ip model and how does KERI fit in the W3C DID standardization?
The ToIP stack has a left side (governance) and the right side (technical)

KERI is at lower levels of the ToIP. Other DID methods will add KERI to their method and that's how KERI could be present in these layers.
- Its goal is to be the missing authentication layer of the internet. That's a pretty well matching objective.
- Layer 1 (settlement layer): Where other
DIDs use blockchains or databases to register identities and settle 'transactions' between between,DDOs, andVCs, KERI uses homegrown native structures:KELandKERL. (@henkvancann) - Layer 2 (communication layer): Non-existing in KERI, because KERI is end-verifiable. KERI can use any other means of communication between actors in the ecosystem
- Layer 3 (transaction layer): Since KERI focuses on the more fundamental part of authentication for the internet, you won't find matching functionality for usual trust-over-IP transaction like VCs or money. VCs (layer 3) relate to KERI only as content hash pointers in KELs, there are no native structures for VCs present in KERI.
- Layer 4 (application layer): Same: KERI is non-existing in this layer.
To summarize: Once we talk DID, we already talk about layers above KERI.
(@henkvancann)
- The KERI developers provisionally design DID:KERI, which might become a mixture of DID:KEY, DID:PEER, and DID:WEB, combinable with more functional DIDs in the Identity spectrum DID:SOV, DID:ETHR, etc.
- No verifiable credentials (@henkvancann)
*Q: What problem is KERI solving? How? And why can't it be solved by other solutions?
KERI solves the problem of secure attribution to identifiers. By using self-certifying identifiers (SCIs) and ambient availability of verifiable Key Event Logs (KEL) that prove authoritative control over identifiers' private keys. It can't be solved by other solutions known so far because those solution have not managed to span identifier interoperability over the internet and function all the same as an overlay.
(@henkvancann)

*Q What is KERI made of?
KERI core
On github KERI[^1] is - and will become even more - a thickening bunch of repositories:
- KERIpy Python Implementation of the KERI Core Libraries
- KERIjs JavaScript (nodes) Implementation of the KERI core library.
- KERIgo Go implementation of KERI (Key Event Receipt Infrastructure)
- KERIox Rust Implementation of the KERI Core Library
- KERI Java Java implementation of KERI
Tools
- KERI Interactive Web Interface
- Wallet
- There is a variety of other tools, of we've described their main reason why the team have chosen them, why they matter to KERI, and why they were preferable above other alternatives in this Development Environment of KERI document.
Draft and Specs
- KERI general Key Event Receipt Infrastructure - the spec and implementation of the KERI protocol
- did:keri
- Composable Event Streaming Representation (CESR) Working area for the individual Internet-Draft
- CESR proof signatures
People
The founder of KERI is Samuel M. Smith Ph.D., operating from his firm prosapien.com. Other people working on KERI can be found via the Github Repos above.
(@henkvancann)
*Q: In what programming languages is KERI available?
In Python and Rust. It was available in Java, Javascript and Go too (2021) but these projects seem to be inactive. Check the last modified dates on their repositories and/or forwards to other projects that those repos have linked. (@henkvancann)
*Q: How does KERI fit in the 10 principles of SSI by Christopher Allen?
KERI is not primarily about self-sovereign identity. KERI is primarily about autonomic identifiers, AIDs. That is: identifiers that are self managing. KERI provides proof of control authority over the identifier. What one does with the identifier is not constrained by KERI. But because the primary root of trust of an AID is a KEL which can be hosted by any infrastructure, any identity system (SSI or otherwise) built on top of KERI may also be portable.
So in my opinion portability of the associated identifiers is essential to any truly self-sovereign identity system.
(SamMSmith)
Where Christopher Allen is talking about portability of information related to the identity, in KERI we take this a step further with the portability of the identifier itself with respect to its supporting infrastructure (aka spanning layer). Most DID methods do not have portable identifiers. They are locked to a given ledger.
(SamMSmith)
*Q: Does KERI cooperate with other projects in the self-sovereign Identity field?
Yes, KERI sat under the Decentralized Identity Foundation, DIF, and was part of the Identity and Discovery Workgroup. In 2021 the increased activity around KERI and its specific nature needed to have an own group within DIF. There are also non-formal relation with the newly launched trust-over-ip foundation, and there's good reasons to fit KERI into trust-over-ip.
In 2022 KERI sits mainly under WebOfTrust, which is a github repository collection of Standards Relating to a Web Of Trust Based on Autonomic Identifier Systems
The integrated work also leads to IETF drafts. The value statement and organizational principles of the IETF strongly resonate with KERI. Read more about why IETF here.
The work is done together with TrustoverIP in the Task Force ACDC. (SamMSmith and @henkvancann)
*Q: What's the difference between a normative and non-normative description or theory?
See the definitions section for what both terms mean. For example, theories of ethics are generally normative - you should not kill, you should help that person, etc. Economics is most commonly non-normative - instead of asking “how should this person choose which goods to buy?”, we are often more interested in “how does this person choose which commodities they buy?”.
**Q: What's the difference between the KERI whitepaper and the KIDs
The whitepaper is the historically grown and expanded design document of KERI.
A [KID] (../kids.md) used to be focussed on Implementation; "this is how we do it" We add commentary to the individual KIDs that elaborate on the why. It has been split from the how to not bother implementors with the why.
The KIDS concept has been abandoned but a remnant of them can still be found here. Now the first thing you should read are the ietf- drafts repos, for example ietf-cesr: https://github.com/WebOfTrust/ietf-cesr(https://github.com/WebOfTrust/ietf-cesr) and ietf-keri: https://github.com/WebOfTrust/ietf-keri.
**Q: What's the status of all the IETF Drafts concerning KERI, CESR, IPEX, ACDC and so on?
When nobody is involved or reads them, how can we be sure it's relevant and becoming a standard?
The goal of the IETF's specification or standard's path is not to drive adoption through a standard. The adoption plan for KERI is:
to build an open source stack of libraries that once completed will largely hide the complexity from the users
Once that stack becomes a defacto standard due to usage then the IETF standard's process will remove other adoption barriers that may arise unless its an official standard of some kind.
Driving adoption by first getting a standard is a very slow very expensive process. Adoption is most rapid when a library is useful and open. IETF is the minimally sufficient standards process that does not interfere with building the KERI stack.
***Q Where is the corresponding KIDS directory for WebOfTrust?
In 2021 "the KIDS quickly felt out of date" (source Phil Feairheller 2022) and the team abandoned the concept for doing the IETF drafts.
Now the place to be for studying technical concepts and technical designs are the ietf- drafts repos, for example (but not exhaustively listed): ietf-cesr and ietf-keri.
*Q: KERI has invented its own key representation and signature format. Why not conforn to current standards already available?
In brief these are these reasons:
- the desire to control the entire stack, and not use anyone else's tooling
- DID and VC layers are the appropriate layers for interoperability
- The performance/security goals of KERI drive its design and therefore KERI can't use so called enveloped data formats
*Q: In the KERI system design trade space you strike out features, so you must have stroked out application space too; which?

KERI's suitability
Not suitable for:
- Applications where total ordering of key event is needed, like in cryptocurrencies and non-fungible tokens.
However, KERI is suitable :
- to build smart contracting in a direct peer-to-peer way
- to build Sidetree with KERI, vice versa is not possible
- to implement blockchain / ledger anchored identifiers (SamMSmith and @henkvancann)
*Q: Are smart contracts possible with KERI?
Yes, KERI gives you the security. And by supplying secure state machines. But you have to gather the right transactions yourself.
Ledgers co-mingle secure state machines into one another, Ledger are total ordering. We don’t need total ordering in KERI. The absence of a ledger gives us the ability to create totally private smart contracts between Bob and Alice.
You use the KERI Duplicity detection to determine the authoritative key is used at a certain point in time.
(@henkvancann)
*Q How does KERI relate to the decentralized identity field?
The concepts in KERI come from many different fields. KERI creator Sam Smith: "The problem KERI faces is that the decentralized identity community is unusually insular and narrow compared to most of the fields I am used to working in. Decentralized Identity experts focus very much on their field, which makes communications about out-of-the-box concepts hard. There also is very little standardization of terminology.
Which I find odd when people complain about KERI's use of terminology. Just ask anyone to define "identity".
This is exacerbated by the recent addition of many who come from the blockchain space who have either a very shallow or narrow understanding of distributed consensus algorithms in spite of spending all their time developing for that space.
Its clear that many if not most have never bothered to read an introductory textbook on the subject and couldn't define liveness or safety or total ordering accurately.
So KERI has an audience that acts as if they understand distributed consensus but have at best a less than rigorous understanding and at worst a largely erroneous understanding. "
Q&A section Why the internet is broken
*Q: Why would the internet be broken?
The Internet Protocol (IP) is broken because it has no security layer.\

(SamMSmith)
**Q: There is no security on the internet?, are you serious?
The security measures the internet has are _bolt-on*s and dependent of intermediary parties. For example the X.509 protocol for DNS. KERI offers a native end-verifiable protocol in a direct (peer-to-peer) and indirect way (duplicity detection in ambient available KERLs). The indirect KERI method removes the need for a middleman, an intermediary, like a Certification Agency for DNS.
*(@henkvancann)_
**Q How can the internet be fixed?
Establish authenticity between the key pair and the identifier of IP packet’s message payload. See more in an explanatory presentation.

(SamMSmith)
*Q: What's wrong with SSL certificate intermediairies?
Administrative Identifier Issuance and Binding; especially the binding between key pair and identifier based on an assertion of an intermediary administrator. This is what's weak and therefore wrong. See more in an explanatory presentation.
(@henkvancann)
**Q: What's DNS Hijacking
A DNS hijacking wave is targeting companies at an almost unprecedented scale. Clever trick allows attackers to obtain valid TLS certificate for hijacked domains. more.
(@henkvancann)
*Q: What is 'platform locked trust' and why should we bother?
The IPv4 layer was become a standard internet transport layers over the years. It is a very strong structure. The transport layer has no security build into it. So the trust layer has to be something higher in the stack. However in the Support Application layers that sit on top of that IPv4, no standardization has taken place yet. It is a highly segmented layer and trust is therefore locked in those segments or platforms; it's not interoperable across the internet. E.g. platform Facebook provides an identity system that only works within their domain. That's the same with for example Google or any number of blockchain.
We don't have a trustable interoperability. And that leads to the idea that the internet is broken. We want to fix that, we don't want a domain segmented internet trust map, a bifurcated internet, we want to have a single trust map. This is the motivation for KERI.
(SamMSmith)
*Q: How to repair the internet trust layer?
With a waist and a neck. 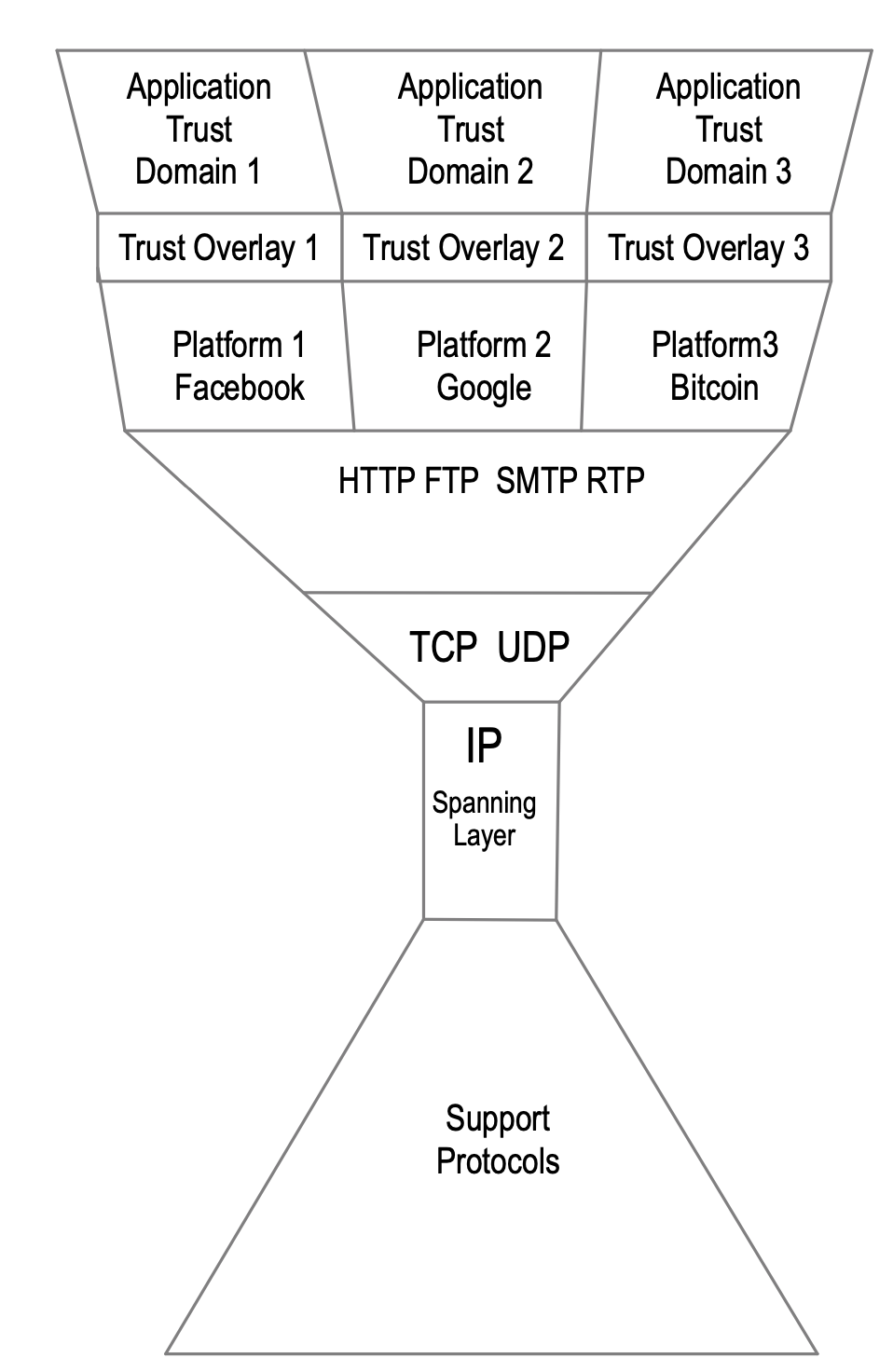
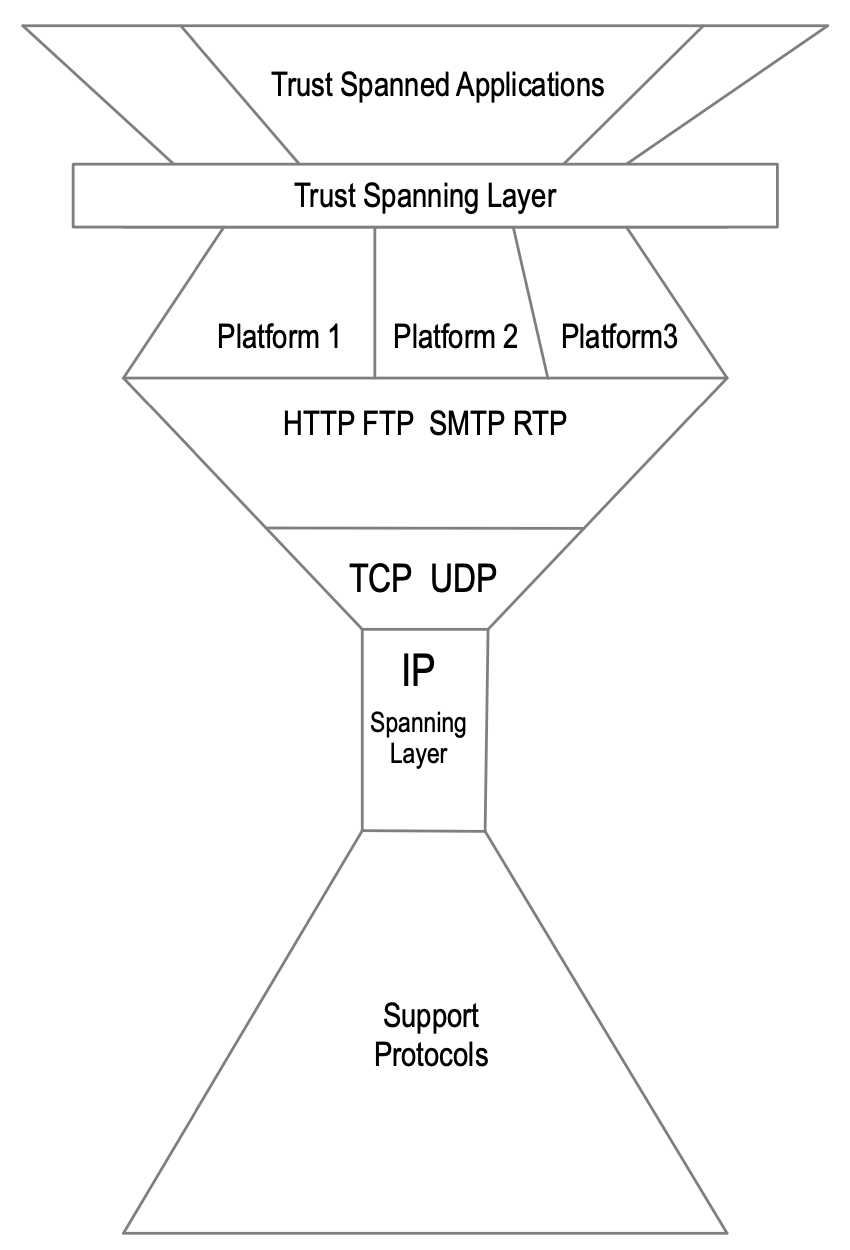 (@henkvancann)
(@henkvancann)
*Q: What role does KERI play in the suggested "repair of the internet"?
Much of the operation of internet infrastructure is inherently decentralized, but control over the value transported across this infrastructure may be much less so.
Centralized value capture systems concentrate value and power and thereby provide both strong temptations for malicious administrators to wield that concentrated power to extract value from participants.
We believe that decentralization of value transfer is essential to building trust. Consequently a key component for a decentralized foundation of trust is an interoperable decentralized identity system. Source: whitepaper page 7
*Q: How does FIDO2 relate to KERI, can KERI be integrated into FIDO2 or the other way around?
FIDO2 could be used for authentication is witnesses - OOBI. FIDO2 is mostly to do more secure authentication factor to federated identifiers like OIDC The problem is the use of barer tokens, they are vulnerable to known attacks. KERI AID replaces FIDO2 key pairs. KERI is better with key rotation. Even the blockchain-based solution did not solve key rotation in a safe way. Source: Sam Smith, May 2024, KERI Suite Zoom Meeting
Open source licenses
*Q: Who is KERI? Is it a company or a not for profit?
KERI sat under the Decentralized Identity Foundation until mid 2021, DIF, in its own working group "KERI".
It had started off in 2020 under the Identity and Discovery Workgroup of DIF.
Due to its licensing structure, KERI isn't owned by anyone and everyone at the same time. The Intellectual Property Right of KERI was hosted with DIF until Mid 2021. It is an open source project. KERI find its IP hosted in IETF from 2021.
**Q: What is the open source licensing policy of KERI?
All the repos in the WoT project where the KERI code and related standards reside, have a 'outgoing == incoming' policy. This means that someones use (outgoing) of a contribution (incoming) is on the same basis or license. This prevents contributions from being poisoned by other contributions that have a different i.e. more restrictive outgoing license, because once contributed there is no way to separate contributions.
**Q: What's wrong with mixing open source licenses while embracing contributions?
It becomes a soup. Have a look below at the Q&A regarding DIF, W3C and KERI.
***Q: What's the difference between split licenses and comprehensive licenses?
And what does KERI prefer?
By comprehensive we mean all contributions of any and all kinds are covered by one license. One can have multiple comprehensive licenses where a given license takes priority for terms but allows for relaxed terms of use in some circumstance. But all contributions are still covered.
In fact any organization including the W3C that has multiple mutually exclusive split licenses instead of one comprehensive license or licenses instead of a set of comprehensive licenses is disputably only viable because of the good will of the contributors.
There just isn’t enough legal precedent to trust such constructions.
So worst case the contribution is no freer than the most restrictive license. Stacking licenses this way is a common legal approach, but splitting is not. Splitting contributions between different licenses is problematic because of the difficulty in defining the boundary. And the worst case is that its not free at all.
**Q: What happened between DIF and KERI with regard to open source licenses?
Under DIF license all source code contributions are apache2. So a pull request from an apache2 licensed repository should not be a problem. Unfortunately, DIF uses a combination of the W3C patent policy and the CC4 license for non-source code contributions and so that is where there is significant ambiguity especially since the W3C Patent Policy as written only provides provisions for management by the W3C, not DIF.
Therefore you can't pull KERI code from DIF into WoT as of June 2022 because in our perspective it's poisoned after this date.
**Q: Can I pull code for DIF and use it at the current WOT repo?
In June of 2022 there was a determination by DIF that there were no patentable contribution to the DIF KERI repo for which the W3C patent policy would apply. So any pull requests from code donated to DIF before June of 2022 are clean. Anything after that we should not accept because there is ambiguity as to what is “source code” and what is not when it comes to contributions at DIF. Frankly I consider DIF’s IP policy to be broken because IMHO there is no way to unambiguously determine if a contribution is source code or not.
Example: Is javascript or python code pasted into an issue raised on DIF’s github repo count as source code and falls under apache2? Or is it text and falls under CCby4, or is it a patentable description of a process?
*Q What are incoming and outgoing licenses?
Incoming means the license that is imposed on contributions (git push). Outgoing means the license adhered to code from WoT, used somewhere else (git pull).
**Q Do incoming and outgoing licenses have the same restriction in KERI?
It is possible to have less restrictive outgoing than incoming or have multiple outgoing licenses that are of the same or less level of restriction but with different names because some consumers want to consume (outgoing) under a different license. This is OK as long as its part of the license structure known by contributors.
Example IETF requires that IETF spec language be contributed under BSD not Apache2. But BSD is no less restrictive than Apache2 for outgoing so it does not poison the apache2 contributions. A consumer can consume under apache2 or via IETF through BSD. BSD is no more restrictive than Apache2. The license for the IETF spec repos in WoT include the BSD outgoing in addition to Apache2 for this reason.
Q&A section KERI and DIDs
**Q: I am just trying to understand the mechanism here, are all AIDs derived from one root private key?
*AIDs are identifiers. Identity may comprise multiple identifiers. So that kind of transfer can always be enacted if the controller controls both AIDs in the trivial sense (ie sign a proof of the old AID with a new AID and rotate the old AID KEL to null keys)_ I mean the prefix would be generated with the use of a salt which would generate a private key, and each peer has one identifier prefix, wouldnt that generated private key become sorta a root private key?
Phil Feairheller — 14/02/2024 18:18 Keys are generated first, using any of the methods described above. So you can have one or multiple private keys and those private keys can each be generated deterministically (using a salt), randomly or contained in a TEE. Then the public keys are derived from the private keys. The same process is followed for the pre-rotated next keys (however many you want).
You then take the public signing keys (first set), digests (currently Blake3) of the pre-rotated keys (second set) and combine them with configuration information into an "inception event". That inception event includes the signing and rotation thresholds, witness AIDs and witness threshold and other configuration information (do-not-delegate, establishment only) and is created as either a JSON, MsgPack or CBOR serialization. You then pad out the d and the i field of the inception event and create a digest (cryptographically agile, so your choice) of that inception event serialization. You then replace the padding of the d and i field with the digest and you have your inception event. Also, the digest (called a SAID in KERI) is your Autonomic Identifier or AID. It has the special properties that it is cryptographically bound (through the hash algorithm) to your first set of signing and rotation keys and it has an "unbounded term". That means that, because you have created pre-rotated keys, you can rotate to new keys and the identifier survives. It is not "bound" by the term of the public keys. In this way we have solved the major problems of current PKI... cryptographic binding of the AID to the keys and secure key rotation.

flowchart TD
%% Henk van Cann, Feb 15th 2024
A["entropy 🎲"];B[random];C["salt 🧂"];D["TEE 💻"];
E["priv key 🙈"]; F["publ key 👁️"]; G["signing 🔑"]; H["pre-rotated 🔑"]
I["digest 📩"]; J["config info 📝"]; K["SCI KEL"]; L["SAID"]
M["SAID KEL ⛓️"]
subgraph one[Key generation]
A -.-> B & C & D
B --> |"Either"|E
C & D --> |"or"|E
E --> |derive| F
end
one -.-> G
one -.-> H
subgraph muliple [Inception event]
subgraph two[Self certifying]
H --> |hash|I
G & I --> K
J --> |JSON|K
end
subgraph three[Self addressing]
L --> |copy in 'd' and 'i' field|M
K --> |pad out 'd' and 'i' field & hash|L
end
two-->three
end
**Q: Is KERI a DID?
KERI is also the name of a DID method in the making Method spec. The proposed related DID method is did:keri. A session at the recent IIW31 presented by Jolocom’s Charles Chunningham examines overlap between data models of DID documents and KERI identifiers here.
Drummond Reed (Dec 2 2020) on did:KERI: "at IIW we asked that question and feedback overwhelmingly favored did:KERI. Furthermore, I’ve proposed that the KERI namespace be reserved within the method-specific ID spaces of other DID methods as well, The Indy community has agreed to reserve the KERI namespace in the Indy DID method."
(@henkvancann)
**Q: Some say that with KERI, a DID can be reduced to did:<identifier>. But that’s not a valid DID?
Every DID must have a method name component before the method-specific ID.
The first paper mentioning the absence of the method is Thinking of DID? KERI On by The Human Colossus Foundation, written by Robert Mitwicki. He addressed the concern in the question (the invalidity of the DID method) and made it more clear what the Foundation meant by that: "We look into the future and with that view we think that namespace could be dropped and we could keep only identifier, as the namespace seems to be one of the major drawbacks of decentralized identifiers at the moment. In my opinion did:KERI:<identifiers> would be just intermediate step as the issue addressed by post would still hold. We see that KERI could be a major upgraded for DID; not replacement."
**Q: Isn't it a bit arrogant of KERI to say "my new DID method is so good that it can replace all others for all eternity"?
But by doing this, you will also exclude a lot of existing identifier infrastructure.
I am not denying existence of existing DID infrastructure, but I agree a lot of them could be obsolete if we introduce KERI. A lot of business models which are build upon current model would be obsolete. I understand that a lot of people would not like that, but that is called progress.
(RobertMitwicki)
Q&A section Wallets
*Q: Why do I need a wallet for KERI?
Yes, a wallet is very much needed. A wallet holds your public private key pairs that embody the root of trust of KERI identifiers. Universal wallet - would do - with a thin layer on top of it.
A wallet needs to be adapted to KERI to be able to carry KERI identifiers.
| TBW |
(SamMSmith) / (CharlesCunningham) / (@henkvancann)
*Q: How can I backup the KERI identifiers in my wallet?
Although KERI is a key management system, it not actually manages the control over and safe deposit of the private keys that control its KELs. KEEP is the tool that manages KERI identifiers' private keys. However, KEEP on its behalf uses an Electron wallet to ultimately store the private keys.
| TBW prio 1 |
(KevinGriffin and @henkvancann)
Can I receive crypto money in my KERI wallet?
We don't need a crypto currency embedded in the KERI system, we can use any other crypto currency system for payment. So the design of the KERI system has left crypto token control out.
(@henkvancann)
*Q: Does a KERI wallet store virtual credentials connect to my identifiers?
The KERI whitepaper has little about virtual credentials and KERI's place in the W3C SSI space for DIDs and VCs. The reason is that KERI is mainly a level 1 and level 2 solution in the trust-over-ip framework.
(@henkvancann)
In the following presentation of SamMSmith, there's a lot information about the relation between KERI and VCs: https://github.com/SmithSamuelM/Papers/blob/master/presentations/GLEIF_with_KERI.web.pdf
Q&A section Signatures
**Q: Who can sign off my proofs and identifiers using KERI?
Depends on what you mean with proof. KERI is content agnostic, so any cryptographic proof can be referenced and signed in a KEL, even a third party signature. As far as KERI-internal proofs are concerned a subject-controller, a delegated controller and combination of (fractioned) multi-signatures can prove authoritative control over a key and over a pre-rotated key. (@henkvancann) | TBW prio 1 |
*Q: What is the practical use of signatures?
In general they can proof the authoritive control over a private key at a certain point back in time. (@henkvancann)
**Q: ‘In the keripy repository what is “sid”, “wan”, “red”
What is the meaning of “sid”, “wan”, and “red” in tests/vc/test_protocoling.py in the test : test_issuing?
Phil Feairheller answers in 2022:
- ian: issuer of cred (start with ‘i’)
- sid: signer of cred (start with ‘s’)
- wan: witnesses (start with ‘w’)
- red: receipient of cred (start with ‘r’)
**Q: Do verifiers, validators, witnesses and watchers all sign off payloads?
Yes they do. For every cause there is a different payload. The main reason why all roles sign off cryptographic references is commitment to those sources (the payload in KERI is often a digest of sources) at a certain point in time.
(@henkvancann)
*Q: What is delegation in KERI and what does it benefit?
KERI identifiers can be “delegated”, meaning one identifier can create another one that can prove its relationship with its parent. This way you can create any hierarchy of identifiers & keys.

**Q: How to sign an ACDC?
Sign the SAID at issuance event.
You don’t sign an ACDC, you anchor it in the KEL via the TEL. Signing the SAID is signing all the content. History: We used to sign ACDC in exchange events, but we later realised that ACDC don’t need to be explicitly signed. So you might find some ACDC signing in older code (before 2023) (@henkvancann)
Q&A section Proofs
*Q: What does KERI proof?
KERI has the ability to proof various things:
- Control over an Autonomous identifier (
AID). - Control over a pre-rotated key
- Commitment to an Event Log
- Content addressing by a hash
- Delegation of control over a key
- | TBW prio 2 |
*Q: Does KERI know whether any message in the Event Logs are valid or true?
No, KERI is data agnostic. KERI does make no statement about the validity of the payload data.
(@henkvancann)
*Q: How can we verify that a statement by a controller is valid?
We may verify that the controller of a private key, made a statement but not the validity of the statement itself.
(SamMSmith)
*Q: How can we trust what was said or written?
We may build trust over time in what was said via histories of verifiably attributable (to whom) consistent statements, i.e. reputation.
(SamMSmith)
*Q: What does "fully signed" mean in KERI?
It means that the required threshold of signatures has been met. It doesn't mean that all signatures have been provided.
**Q: Do I need to show the full log (KEL) to anybody I transact with, even though I'd only like to show a part of it, for example a virtual credential?
Yes, because they can't verify the root of trust. They have to have access to the full log at some point in time. Once they verified to the root of trust, once, they don't have to keep a copy of the full log. They have to keep the event they've seen and any event since, that they need to verify as they go. (SamMSmith)
**Q: What's the difference between interactive - and non-interactive proof (for example proof of Authentication)
Interactive proof of authentication requires both parties interacting, it uses bandwidth, I can't batch the interactions either. So it's not scalable.
Non-interactive proof of authentication -> digital signature with public private key pair.
Non-interactive has huge advantages for scalability.
The weakness is of non-interactive proving is replay attack ( the interactive method has built-in mechanism to prevent replay attacks ).
Replay attack is some adversary is replaying a request for access in your name after having gained access to your private keys.
Solution to replay attack is both Uniqueness and Timeliness.
Aspects
Uniqueness
Uniqueness works with a nonce, that's being obtained by a challenge-response mechanism and the requester has to use that nonce to seal the request.
Timeliness
Timeliness is even better because it can service both properties needed in one go. If we use a Date-time-stamp (monotonic) in time window we can be sure that the sender request is unique and has been established in an acceptable time frame.
So therefore the non-interactive mechanism to replay attack prevention has been suggested in KERI implemented by Date-time-stamp (monotonic).
The time window can be fairly large because you use monotonicity.
How can I use KERI to filter connections with the outside world? Any public enquiry should be filtered upfront
My e-mail address or phone number are publicly available and anyone can contact me, I'd like more privacy.
I you want to talk to me, you send a message to my public identifier.
First use a public identifier and then set up a private pairwise connection.
You don't need to a strong correlation of your public identifier to you as an entity, but only to your "local" reputation, expressed by the KEL itself.
The correlation in KERI is never public, always private. Spam goes away because of the provable attestation.
(SamMSmith) and (@Chunningham)
*Q: How does KERI handle double claims?
In short, it doesn't because KERI is context free, for a reason and that is privacy. So you could make double claims.
***Q: How can I implement a mechanism in KERI that tracks double claims?
KERI's purpose isn't to solve transaction state, other than key state. KERI doesn't care about the semantics about what is anchored in KERI. So if you want to solve a double claim problem in a given transaction context, then you create a transaction event log (TEL) for that context, where you could enforce priority in that TEL that you make claim then that claim has an identifier. You attach some semantics to your transaction set: which types of claims in this specific context. This is transaction context specific and allows to control it.
This fits nicely in the thin layering model of KERI because the authority for making any claim in a TEL can be establish back to the KEL.
(SamMSmith)
Transaction state is a more local consideration. One layer up (TELs are where they live, and a specific context/network/cloud/etc can set up its own ordered ledger of transactions using TELs; claims to authoritative txn state limited by such opt-in/perimeter-bound txn consensus).
Claims need an identifier to be assigned semantics. If claims or semantics are human readable we need case-based reasoning and very sophisticated AI with natural-language processors.
(@bumblefudge)
Each layer in KERI is responsible for its own duplicity detection!
(@stevetodd)
**Q: What choices do I have implementing claims in KERI and offer double claim detection to verifiers?
If a controller choses to hash its claims, the controller choses for hiding (and the ability to double claim!), which is perfectly fine with KERI because KERI is privacy preserving.
Alternatively, suppose the controller choses to implement the solution mentioned above and create specific type of transaction context, and offers means of detect duplicity in statements (in this case double claims in transaction event log, also TEL), e.g. "Are you for - or against nuclear power" and the allowed options are Yes or No. In this case especially time is relevant. Certain contradictory claims about a topic can be made within a certain time span. One could change his/her mind about about a certain topic, and anchor this change of mind in a KERI transaction event log (also TEL).
It's up to verifiers to judge this softer version of duplicity at the context level within TELs, which means: how quickly can one change one's mind and still be trustworthy.
If a verifier with the help of AI were to find out a controller is stretching honesty to swabbing about a topic, for example creating two TELs with semantically the same context but obfuscated by few typos and alternative formulation (example: "Like nuclear power?" Y/N) then trust is down to near zero.
(@henkvancann)
Q&A section Private Key Management
**Q: Why hasn't PGP and GPG never really caught on well?
The first reason is that people are not interested in key management if it doesn't concern money. Only since we have crypto currencies the management of private keys has taken off. And for decentralized identities we can go with the flow of that success. Hierarchical deterministic keys are now wide spread among the early adopters of crypto currencies. They are based on 24-word so called seeds (also called 'mnemonic phrase') and password, with the aid of (hardware) wallets. And the only reason why it has been such a great success compared to the decennia old PGP, seems to be that loss of crypto money is much stronger felt than the loss or exposure of private personal data.
A second reason is the method of verification and attestation in the PGP web-of-trust doesn't scale and it's difficult to use. The user interface of GPG isn't up to our beyond 2010 standards at all.
**Q: Can I use a PGP public private key pair for KERI?
In theory we could list a PGP public key in the KERI KID0001 - Prefixes, Derivation and derivation reference tables.
| TBW prio 3: Old reference to abandoned KIDs at DIF, renew |
However it's not very practical, because PGP itself is a conglomerate format that has its own derivation codes on board for different cryptographic functions. That means the PGP public key already has protocol semantic on board and that's one layer higher up than what we need for KERI in the key data structure design. KERI has it's own derivation codes and the minimization design principle dictates that it makes no sense to support PGP, because as an inception key pair for KERI it has no added value, and it has redundancy on board.
(@henkvancann)
| TBW 3 |
**Q: What difference does the Autonomic Architecture of the KERI Identity System make?
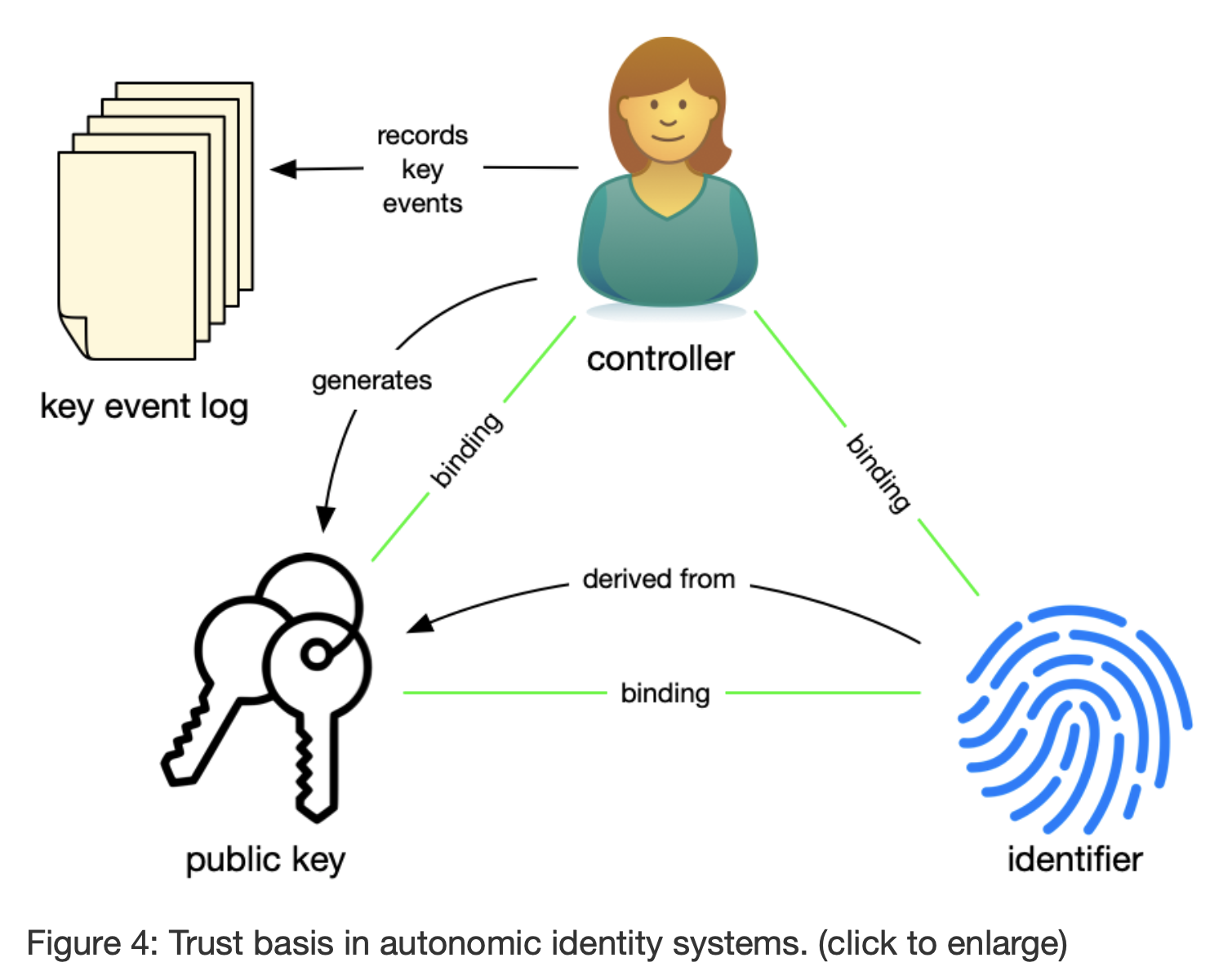
The controller uses her private key to authoritatively and non-repudiated sign statements about the operations on the keys and their binding to the identifier, storing those in an ordered key event log (KEL). One of the important realizations that make autonomic identity systems possible is that the key event log must only be ordered in the context of a single identifier, not globally. So, a ledger is not needed for recording operations on identifiers that are not public. The key event log can be shared with and verified by anyone who cares to see it.
The controller also uses the private key to sign statements that authenticate herself and authorize use of the identifier. A digital signature also provides the means of cryptographically responding to challenges to prove her control of the identifier. These self-authentication and self-authorization capabilities make the identifier self-certifying and self-managing, meaning that there is no external third party, not even a ledger, needed for the controller to manage and use the identifier and prove to others the integrity of the bindings between herself and the identifier. Thus anyone (any entity) can create and establish control over an identifier namespace in a manner that is independent, interoperable, and portable without recourse to any central authority. Autonomic identity systems rely solely on self-sovereign authority.
(@windley)
More in The Architecture of Identity Systems
**Q: How multi-tasking is the key infrastructure?
KERI has univalent, bivalent and multivalent infrastructures. Definitions from the keri whitepaper: \
9.5.1 Key Management Infrastructure Valence
When all storage and signing operations both administrative and not are supported by one computing device or component we call this a univalent architecture or infrastructure. When storage and signing operations are split between two computing devices or components, we call this a bivalent architecture or infrastructure. In general when storage and signing are split between two or more key computing devices or components, we call this a multivalent architecture or infrastructure.

You need Key-pair Generation and Key-Event-Signing Infrastructure. And KERI doesn't care how you do it.
From bivalent delegation | fill out?! | comes into play. But in fact you can have multivalent infrastructures, all with their own security guarantees and its own key management policies.
It's all one KERI codebase to do all these infrastructures.
(SamMSmith)
*Q: Does your public-private-key format matter in KERI?
No, because the derivation code allows you to use whichever format you want. So anyone that sees an identifier looks at the first byte or two bytes pre-pended, it's a derived code, and you can tell exactly what type of public-private-key format we have, e.g. ecdsa.
When you rotate keys, you can always rotate to a different format.
*Q: Can I use BIP32 Hierarchical deterministic keys in KERI to rotate?
Yes, you can derive your keys from that scheme. But KERI is agnostic about it, it wouldn't know.
*Q: Not your keys, not your identity?
To begin with, yes, KERI fully depends on PKI cryptography. KERI was built upon the assumption of unbreakable public private keys.

By the way, in KERI we say identifier, because identity is a loaded term, lots of misunderstanding around it.
Pre rotated keys are best practice to keep control of your identifiers.
If you lose unique control of a key right after inception, before rotation, are there no guarantees to be given for KERLs via witnesses / watchers or whatever. Is the only thing you can do about it, is revoke the key in that case? |
(@henkvancann)
*Q: A wallet is there to store my KERI private keys safely, no?
Currently Universal wallet is aimed at to store KERI keys. The vast majority of security breaches or exposures of keys are originated by the behavior of people: the way they use wallets. Most rarely due to errors in the wallet software. | TBW prio 1 |
**Q: Are compound private keys (Shamir Secret Sharing) and multi signature schemes possible to incept identifiers?
Yes, complex fractional structures are natively possible in KERI. However only for the non-basic forms (for transferable identifiers).
(@henkvancann)
| TBW prio 1 |
**Q: How to delegate control over my private keys that control my identifiers?
In KERI you would never hand over control over your private keys, but always create delegated keys (a kind of "sub"keys lower in the hierarchy). Delegated keys are a secondary root-of-trust within KERI. (@henkvancann) | TBW prio 3 |
*Q: How can I create a private key for my two years old son?
And start a KERI public identifier for him. The associated identifier receives and holds value, and that nobody can control except for my son, when he's able to manage the keys.
At some point in time somebody always has authoritative control of identifiers, or simply put "controls the key" or "has the private key" to the value. But one can organize Guardianship. A Deeper Understanding of Implementing Guardianship at SovrinFoundation and Aries RFCs they’ve informed us with an overview at last IIW (notes).
The Sovrin Guardianship Working group site is here
*Q: How can I create a private key for my sixteen years old daughter who is not an adult?
And start a KERI public identifier for her.
It is a legal issue, there can only be one person holding keys. Either the parent or the child holds the key.
The problem has to do with temporary guardianship. You need to implement an additional legal construct like the ones mentioned above. After that a set of governors have control authority.
Other constructions like multi sign or sharing schemes (e.g. Shamir SSS) introduce more parties and more complexity and are not advised.
**Q: How do I organize guardianship over keys meant for somebody else to control at a later stage under specific circumstances?
A set of related, and widely supported within the DID community, ideas by TNO The Netherlands in a whitepaper 'Decentralized SSI Governance, the missing link in automating business decisions', that we collectively refer to as “decentralized SSI governance”.
Q&A section Blockchain
*Q: Does KERI use a blockchain?
No, but KERI uses the same cryptographic building blocks as blockchains do.
(@henkvancann)
However, KERI may be augmented with distributed consensus ledgers but does not require them. Source: section conclusion in whitepaper
**Q: What's the difference between KERI and blockchain?
KERI is a unordered hash-linked list of signed Key Event logs and blockchain is a timestamped ordered list of hash-linked blocks of signed transactions. What this means:
- we don't need ordering in
KERIand that frees us from consensus protocols in blockchains - Hash-linking is done on a lower level in
KERIand preserves consistency and fuels revealing of duplicity. - In
KERIproofs are cryptographically derived from the root of trust, being the autonomous controller, in blockchains the root-of-trust is a transaction on a ledger; that means the Identifier gets locked on the ledger.
(@henkvancann)
**Q: Why not register identities on an open public ledger like bitcoin, ethereum or soverin?
Because for our purposes we don't need to. Consider two distinct identifier to totally ordered, distributed consensus ledger:
- the access identifier that allows you to access the ledger. This one is usually a
SCI. E.g. on bitcoin your bitcoin address is cryptographically derived from the public key from your key pair. - the register identifier that allows you to register an identifier on the ledger. The ledger transaction is validated registering of your identifier, not the cryptographic root-of-trust that the access identifier is using.
The identifier is now locked to that ledger. We want identifiers to be portable across ledgers, so we don't want to use registration as the root-of-trust, we want to be self-certified all the way. (SamMSmith)
**Q: KERI is basically a series of Pay2PublicKeyHash transactions?
that you send to witnesses, who observe them and attest to the particular line of operations they see?
In brief: for KERI that is an apples and oranges comparison.
Because total linear ordering is not needed for a given identifier's event sequencing. Only linear order of that identifier's history. The histories from other events do not have to be ordered with respect to each other. So the secure ordering of a given identifier's history is a completely different class of problem than the secure total ordering of commingled history from multiple identifiers.
The security demands are less for the former case. So the equivalent security may be obtained in other ways. While the latter as a side effect of total ordering gives local ordering (per identifier) for free. But securing total ordering may be much harder to do. So one has to be careful, because it's no longer an apples to apples comparison.
(SamMSmith)
*Q: Wouldn’t we still need public blockchains to hash proof?
At least at certain intervals to ensure my data is not erased by the central registry...
The registry is logically centralized (in that there is a consensus between participants) but there is no central registry (needed, ed.), which gate-keeps access to the data.
(@Chunningham)
*Q: How do I explain the significance of KERI's blockchain-less-ness?
In brief: identifier portability is significant.
The key answer to How can you control your own online identity? is that it must be portable. The system must have the property of identifier portability.
This is analogous to the property that mobile telephone numbers now have (but didn't have for decades) that is number portability between providers. Likewise a blockchain based identity system suffers from the lack of identifier portability.
It doesn't matter that the blockchain has a decentralized governance structure, the identifier is not portable and so the user is not truly totally sovereign over their identifiers and hence their identity based on those identifiers. KERI is a system able to globally authenticate and that supports global portability.
Q&A section Root of trust
**Q: What do I need to trust in KERI?
Primary root of trust is KEL not secondary (starts with self cert ID), but then after the first rotation, if any, you must have a KEL.
(SamMSmith)
**Q: What is the difference between a trust basis and a trust domain?
A trust basis binds controllers, identifiers, and key-pairs.
A trust domain is the ecosystem of interactions that rely on a trust basis.
***Q: KERI does not need a blockchain, but how does it establish the root-of-trust that we need for SSI? How does the data persist?
The KELs are what establishes the root of trust in KERI. So you have a SCI and a KEL. The KEL is ordered with respect to the SCI by the controller. You don't need total ordering with respect to other identifiers to establish the root of trust in KERI, because the controller is the one and only, who orders events.
In blockchains you have total ordering, which you need for double spend protecting in cryptocurrencies, but not in KERI.
For people in blockchain this is a bit hard to grasp, but we don’t need hash chained data structure of events on single identifier nor the ordering those, I just need logs, I need append-only logs of events to establish the authority.
And so I defend myself against duplicity.
(SamMSmith)
**Q: Why is end-verifiability such a big thing in KERI?
In brief: with end-verifiability anyone can verify anywhere at anytime, without the need to trust anyone or anything in between.
Because any copy of an end-verifiable record or log is sufficient, any infrastructure providing a copy is replaceable by any other infrastructure that provides a copy, that is, any infrastructure may do. Therefore the infrastructure used to maintain a log of transfer statements is merely a secondary root-of-trust for control establishment over the identifier. This enables the use of ambient infrastructure to provide a copy of the log. The combination of end verifiable logs served by ambient infrastructure enables ambient verifiability, that is, anyone can verify anywhere at anytime. This approach exhibits some of the features of certificate transparency and key transparency with end-verifiable event logs but differs in that each identifier has its own chain of events that are rooted in a self-certifying identifier.
Q&A section KERI operational
*Q: Where can I download KERI?
On (sub)page(s of) github.
*Q: Where can we find the code and how could a coder get started?
The homepage on github [README.md] (../README) pretty much sums up all the possibilities to download the available code and how developers can currently engage in the development process. We welcome all help we can get.
*Q: What would you see as the main drawback of KERI?
- Its main drawback is that it's nascent. (SamMSmith)
- The field of cryptography is already complex by itself. KERI's extended complexity, combined with totally new terms and new process description make it a steep learning curve. It depends on your individual drive to want to know about KERI, to what extent the effort pays off. Maybe first try:
- [KERI made easy] (./KERI-made-easy.md)
- The general [KERI Q&A] (./q-and-a.md) (@henkvancann)
- KERI is inventing its own lowest level building blocks. That will prevent a lot of potential code reuse. (@OR13)
*Q: Where you would need something quite different than KERI?
KERI does one thing, it establishes control authority using verifiable portable proofs that are KELs.
(SamMSmith)
*Q: How does KERI scale
KEL, KERL and KAACE might well be very lean alternatives to blockchain based solutions. The hard part is the ambient verifiable architecture.
(@henkvancann)
*Q: Is KERI post-quantum secure?
In brief: yes, pre-rotation with hashed public keys and strong one-way hash functions are post-quantum secure.
Post-quantum cryptography deals with techniques that maintain their cryptographic strength despite attack from quantum computers. Because it is currently assumed that practical quantum computers do not yet exist, post-quantum techniques are forward looking to some future time when they do exist. A one-way function that is post- quantum secure will not be any less secure (resistant to inversion) in the event that practical quantum computers suddenly or unexpectedly become available. One class of post-quantum secure one-way functions are some cryptographic strength hashes. The analysis of D.J. Bernstein with regards the collision resistance of cryptographic one-way hashing functions concludes that quantum computation provides no advantage over non-quantum techniques.
Strong one-way hash functions, such as 256 bit (32 byte) Blake2, Blake3 and SHA3, with 128 bits of pre-quantum strength maintain that strength post-quantum.
Source: whitepaper page 65
*Q: What happens if I or other people are offline?
Any controller can install a Service/Agent Log, controlled by them.
*Q: How to handle multiple formats of KEL and KERL through time. Will they be backwards compatible?
| TBW prio 2 |
*Q: How to bootstrap KERI on the internet? Is it like fax machine; the more KELs there are, the more effective it is?
Any subject / controller can start creating KERI events in a KERI event log. Dependent of the objectives a controller has with KERI a more peer-to-peer (one-to-one) approach or contrary to that a one to many approach. In the latter case a set of witnesses and their services can emerge per controller. Subsequently one or more verifiers (and their watchers) can also enter the play. The more entities are getting used to play the different KERI specific roles the more rapid and easy will the bootstrapping / flooding of KERI on the internet evolve. | TBW prio 1 |
*Q: Is there a KERI course or webinar available?
The SSI Meetup webinar on KERI took place in May 2020 and is a good lesson and source of information.
There is lots of course material available on prosapien.com.
(@henkvancann)
*Q: Is KERI fast enough? How does its speed relate to blockchains like Bitcoin and Indy and payment processors like VISA?
In short, KERI is three to four orders of magnitude faster than its functional equivalents.
An important note is KERI is not a crypto-currency. It's a Key Event Receipt Infrastructure that operates at a lower level than most crypto currencies and Decentralized Identity systems, hence you can rebuild those systems with KERI.
A second note is that speed and scalability is often a trade-off with several other parameters like security, decentralization, useability. Nevertheless we'll try to answer the question in general terms and correct in orders of magnitude.
A public blockchain like Bitcoin or Ethereum has a transaction speed in the single digits up to the hundreds transactions per second (TPS). Permission-ed blockchains can deliver transaction speed in one to two orders of magnitudes higher.
KERI is permission-less, scalable, secure and has transactions of events in order of magnitude four times higher than public blockchains (10.000 times more) and in the range of VISA credit card transactions. KERIs speed is mainly dependent of the number of controllers that have to mutually verify their KELs.
The problem with blockchain based solution like Indy is that they do not offer concurrent processing in their code. They will hit a performance and scalability cieling within the range of the thousands of (event-) transactions.
Based on IIW32 recordings of session
KERI: Centralized Registry with Decentralized Control (KEL & TEL ) + DEMO
(@henkvancann)
*Q: Could KERI work for edge computers that need self sovereign identity? How to (selectively) share control over the SCI/SAI with the owners of the device?
Delegation could be used. There is an issue about IoT key and identifier management with KERI that answers this question profoundly.
(SamMSmith)
*Q: Can a holder revoke a virtual credential (VC) instead of the issuer/controller?
There a two sorts of issuances of credentials:
- A public statement (e.g. provenance of data), or
- the presentation of an authorization
The former doesn't have a holder. So we focus on the main use of
VCs: the latter: the presentation of an authorization.
Usually holders don't revoke a credential, they just decide to not use them anymore. You could install a Policy and a set of Rules to give holders to exercise power to some extent over the revocation:
- Policy: a holder can ask the entity that has authoritative control over the
VCs to revoke it. - Rules: for a TEL , for example cooperative delegation through delegated identifiers to participate in a revocation event, where both the holder and the issuer have to participate, but you could change the rules so that either party could revoke.
Based on IIW32 recordings of session KERI: Centralized Registry with Decentralized Control (KEL & TEL ) + DEMO
(@henkvancann)
Q&A section Agencies
**Q: What does the governance framework of KERI look like?
Decentralized systems must coordinate across multiple parties, all acting independently in their own self-interest. This means that the rules of engagement and interaction must be spelled out and agreed to ahead of time, with incentives, disincentives, consequences, processes, and procedures made clear. | TBW prio 3 | DRAFT BY (@henkvancann)
KERI is self-administered, self-governed. What aspects of KERI need governance?
Purist permission-less network proponents will argue that a real decentralized network does not need a governance framework since mathematics and cryptography make sure that proper governance is in place.
The Trust over IP stack includes both a governance stack and technology stack.
KERI governance roles at Layer 1 can include
- Controller, Entropy hardware and software, KEL, KERL
Layer 2: Provider governance frameworks
- Governance of capabilities of digital wallets, agents, and agencies. So the need is primarily to establish baseline security, privacy, and data protection requirements, plus interoperability testing and certification programs, for the following roles:
- Hardware Developers: hardware security modules (HSMs)
- Software Developers: duplicity verification and internal consistency checks
- Agency: ambient availability of KELs and KERLs
Layer 3: Credential governance frameworks
KERI is not an outspoken credential issuance and verification framework. Having said that:
- Controller: inception proof, revocation, delegation proof
- Holders: availability
- Verifier: external inconsistency proofs
Layer 4: Ecosystem governance framework
- KERIs objective is to be the spanning trust infrastructure of the whole internet
- Portability of the identities and KERI interoperability between platforms is cryptographically secured
- Inconsistencies "reported" by meerkats -like alert governance system
**Q: How can KERI offer consistent services and truth?
A. In a pair-wise setting each party only needs to be consistent with the other party. Witnesses are not used. It doesn't matter if they lie to each other as long as they lie consistently. KERI does not
enable someone to proof the veracity of a statement only the authenticity of the statement.
(SamMSmith)
B. If 3 parties are involved in a transaction all they need do is query each other for the copy of the KEL that each is using for each other to ensure that there is no duplicity.
(SamMSmith)
C. To guarantee undetectable duplicity requires a successful eclipse attack on all the parties. KERI merely requires that there be sufficient duplicity detection in the ecosystem.
This would be a set of watchers that the validators trust that record any and all copies of key event logs (KEL) that they see. Because these watchers can be anyone and anywhere, any controller of a public identifier is at peril should they choose to publish inconsistent copies of their KEL. This removes the incentive to be duplicitous.
Any blockchain system is also vulnerable to such an eclipse attack.
(SamMSmith)
Q&A Virtual Credentials
*Q: Why doesn't KERI use certification as a root of trust?
Why do we want portable identifiers instead of the Ledger Locked IDs, since we have DIDs that can resolve a ledger locked Id uniformly? You say “We don’t want to use certification as a root of trust, we want to do it self-certified all the way” -> what about the issuance of a credential based on the ledger locking, isn’t that beneficial?
*Q: Is Custodianship of KERI identifiers possible?
Or does (Delegated, Multi-sig) Self-Addressing do the job? | TBW Prio 2 |
Acknowledgements
Platypus - Welcome Collection gallery (2018-03-21): https://wellcomecollection.org/works/w3wxxrtv CC-BY-4.0