Q&A about KERI's Security model and Guarantees
This document is part two of Q-and-A. Both files shares a common Glossary, KERI specific and more generic decentralized Identity ones, that has:
- an alphabetically ordered list of abbreviations
- an alphabetically ordered list of definitions
The questions are of a varied level: basic and detailed. The answers are mostly directed towards generally interested people and newbies.
*Q = one star question. Novice to KERI, advanced in DIDs
Q = two star question. Proficient in DIDs and advanced in KERI
*Q = three star question. Expert in DIDs and proficient in KERI
Why should you read or step through the Q&A? To get a different angle to the same topic: KERI.
{TBW} means: to be written
{TBW prio 1} means to be written with the highest priority,
3 = no urgency, 2 = intermediate
Inspired by presentation given and questions asked on the SSI webinar May 2020, but also issues raised and the progress made, here on Github (Turn on 'Watch' if you want to be notified of conversations).
Beware: A Q&A is always work in progress. Tips & help welcome.
Disclaimer
Some of the respondents in the open repo and presentations have been explicitly named as a source, like Samuel M. Smith Ph.D., Charles Cunningham, and Orie Steel. If there is no reference added to the answers, then it's a mixture of sources and edits in the question. Most of the editing is done by @henkvancann, which might have introduced omission, errors, language glitches and such. Sorry for that, feel free to correct by submitting a pull request (PR).
For practical reasons educational images uploaded by Github members have been downloaded. We de-personalized them by giving images a new name. Under these new names these images have been uploaded to github and used in the Q&A to clarify the questions and answers.
Keri's content is licensed under the CC by SA 4.0. license. Parts of the video offered on SSI Meetup webinar 58 have been captured and uploaded to Github to support the answers to general questions about digital identity and more in depth answers to question about Keri.
We've done our best to protect the privacy of the Github by investigating the images we used. We haven't come across personal identifiable information (pii). However, should we have made a mistake after all, please let us know and we'll correct this immediately.
List of questions and definitions
TBW
Knowledge you should be confidently applying
- The definitions in the glossary
- The Knowledge you should be confidently applying from part one of the Q-and-A
- Bitcoin Improvement Protocols: BIP32, BIP39, BIP44, BIP47, BIP49, BIP84, BIP174
- hierarchical deterministic derivation paths
- Base58
- Eliptic curves
- W3C DIDs thoroughly
Actions you should be comfortable with
- The Actions you should be comfortable with from part one of the Q-and-A
- Amend knowledge and keep existing knowledge up to date
Jump table to categories
PART TWO SECURITY
- Q&A section KERI security considerations
- KERI operational security
- Identifiers
- Event logs
- Inconsistency and duplicity
- Key rotation
- KEL and KERL
- Witness
- Watchers
- KERI and blockchain settled DIDs
- Security Guarantees
PART ONE
- General
- Why the internet is broken
- Open source licenses
- KERI and DIDs
- Wallets
- Signatures
- Proofs
- Private Key Management
- Blockchain
- KERI operational
- Root of trust
- Agencies
- Virtual Credentials
Q&A section KERI security considerations
**Q: As an SSI expert I totally can get stuck in the semantics of KERI. How to overcome this?
If we could sit down with every expert and walk through his concerns, it would change. Our biggest problem is that when we write technical stuff, we are writing for an imagined technical audience that cares about the same things at the same technical level that we care about.
In other words our default audience is ourselves (in the KERI team). It reminds us what we thought at the time of writing.
Even if we are writing for a known audience, we can't adapt in real time, because its not interactive so we usually only get it half right, just half convincing, which is as good as nothing in internet security.
But when we talk to people one-on-one we can adapt what we say to match their level of understanding and what they care about. In real time. We can go as deep as needed but no deeper or a broad as needed but no broader.
**Q: Why is KERI so confusing, even for SSI experts?
KERI is confusing because it is new and can' be assumed. Whole books exists and hundreds of papers on "eventual consistency" algorithms (which CouchDB uses) but they are just assumed away. Because KERI is new, I can't just assume it away. But KERI is not magic or scary or anywhere as near as difficult as BFT BA which is assumed away or PoW which is also assumed away. Conversely, most people make assumptions about the security guarantees of DLT that are false. There are many papers on all the known active compromises to Bitcoin that happen on a regular basis yet they assume that they can't happen.
**Q: Why would KERI's creator be fit to fulfil the KERI claims?
Much of Sam Smith's career he has spent working in a multidisciplinary field that used to be called Computational Intelligence (because A.I. was a hype term) which included as sub fields, Intelligent Control Systems, Automated Reasoning Systems, and Distributed Cooperative Control Systems, to name a few.
All of which used some form of machine learning as a subset. Smith then branched out into IoT distributed systems that employed machine learning for self-healing routing algorithms and simultaneously spent many years working on open standard communications protocols including designing and developing two new protocols largely on my own. One was a highly scalable performant end-to-end secure internet protocol called RAET (Circa 2014). This gives him a uniquely well suited experience base to solve the problem that KERI solves.
**Q: Why are KERI security claims struggling to get appreciation in the Decentralized Identity space?
KERI solves a really really hard problem that many of the experts in the Decentralized Identity field do not have the background to easily understand. They are going to have to invest some effort to either acquire that background or be patient enough to walk through lengthy tutorials. There is no short cut. KERI creator Sam Smith: "There were a dozen people at IIW April 2021 that sat through three hours of the KERI security sessions where I patiently walked through it. But we only covered half a dozen of the meta security issues and could easily spend another three hours covering several more and many more covering the micro security issues. But most will never take that much time."
Lots of experts in the Decentralized Identity field have extremely deep understanding of legacy IT tech but have a very shallow understanding of crypto, real key management, and distributed consensus. So they are not yet equipped well enough to design decentralized identity systems,
despite their 30+ years of working in the identity space. The future of distributed security is based on something called zero trust computing and many of these same experts in the Decentralized Identity field have a best a passing familiarity with what zero trust means.
**Q: What is KERI's most important critique on the Decentralized Identity space?
Although the Decentralized Identity space is young, it's already pretty biased and sometimes narrow minded. The solutions in the DID space also have fundamental flaws. We will argue for both claims.
DID expert tend to not read and re-invent what KERI is all about. See here how the KERI community would like to be handled.
Fundamental flaws:
- Any KERI user gets to decide, e.g. over transaction events. The root-of-trust and the key state is at a lower level always in KERI. You don't co-mingle those. Which is probably the biggest design flaw of most what we see in the Decentralized Identity community where they co-mingle control state and key state with transaction state with means they are locked together.
- The number of DID methods seems to explode all with their own security characteristics, which makes interoperability a chain as strong as the weakest link.
- The DID community has embraced (public) blockchains to get rid of the middle men. Apart from the question whether that could be a successful approach we see that for those experts it's particularly hard to wrap their heads around the KERI security concept, which is scalable to VISA speed, doesn't need a blockchain and can be used to re-design 95+% of all the DID methods by using KERI under the hood. (@henkvancann)
**Q: Why would the world be a better place with KERI than without?
We know of no general solution to the portable secure attribution problem before KERI. The DNS/CA system is a general solution to the attribution problem but its not portable and its not secure. (it was meant to be secure but failed, it was never meant to be portable) DLT based systems may provide more or less secure solutions but not portable ones. The combination of portability and security is really really hard.
**Q; What does it take to get it, even for experts?
The KERI solution requires highly nuanced understanding of the underlying properties of distributed security systems.
Which means broad and deep understanding of distributed systems, distributed consensus algorithms, cryptographic systems and distributed key management systems.
**Q; What's that background of KERI's creator Samuel Smith?
Sam spent years doing sponsored research in a multi-disciplinary field where every meeting he went to was filled with PhDs from big name universities.
He represented a small name university, in order to compete he had to study both more widely and more deeply than his competition.
This penchant for deep diving every time he encounter something new has served him well throughout his career.
Smith has built up thorough understanding of:
- distributed systems,
- distributed consensus algorithms,
- cryptographic systems and
- distributed key management systems.
Six years ago when he started in the identity space, he already had 20+ years in the first two, a couple of years in the second two and then have spent much of the last six years deepening my understanding in the last two and innovating across all four.
It is comprehensible that Sam can't begin to replicate that experience/knowledge base in a few thousand pages, much less a few hundred pages of writing.
More on Sam Smith's career on LinkedIN
Q&A section KERI operational security
*Q: What is the primary root-of-trust?
In KERI a root-of-trust is cryptographically verifiable all the way to its current controlling key pair in a PKI.
The characteristic primary is one-on-one related to the entropy used for the creation of (the seed of) the private keys. (@henkvancann)
**Q: How can we know if random generators in crypto libraries are good or not
Is there a list of libraries that we should consider using in out projects, or a list of the ones that we should never use?
In brief:
In every cryptographic system entropy rules, and if you don't use a good rng (a csprng) you're boned from the start. This is really important for everyone in the space to understand.
Generally you want to use the one supplied by the operating system. In linux this used to be /dev/urandom.
In Rust you typically use OsRng from the random crate in fashion. In cesride we rely on two variants due to the expectations of ed25519-dalek and k256, and we simply pass them to the libraries to generate keys.
You'd need to investigate how to get random bits in whatever language you are using, and just make sure what you are reading is about a csprng and not just an rng or prng.
This looks like it has a lot of good info: https://crypto.stackexchange.com/questions/11345/definition-of-a-csprng
And, even a good csprng should be seeded well - if you can get random data from measuring user input or environmental conditions that can't be easily controlled you will generally be more resistant to attack.
Think about the case for example, where a designer is tempted to use a radio receiver and noise to seed the RNG, but an attacker floods the space with a frequency that produces a deterministic result in the ADC or something.
(Source: Jason Colburne, Feb 2023)
In KERIpy we use libsodium through the python bindings. I've never actually looked at what their documentation says about randomness, but here it is: The library provides a set of functions to generate unpredictable data, suitable for creating secret keys.
- On Windows systems, the
RtlGenRandom()function is used. - On OpenBSD and Bitrig, the
arc4random()function is used. - On recent FreeBSD and Linux kernels, the
getrandomsystem call is used. - On other Unices, the
/dev/urandomdevice is used.
(Source: Philip Feairheller, Feb 2023)
*Q: What is the main component of KERI's security?
Key management is the main component, because every attack on KERI starts with key compromise. In KERI that is strictly defined and has a few caveats. There are no other attacks possible because KERI has consistent logs that are cryptographic verifiable to the root-of-trust, also know as the public private key pair used to create the identifier.\
So when we say “key compromise” in KERI we really mean compromise of one of these three things: Three infrastructures that are included in “key management” systems that must be protected.
- Key pair creation and storage
- Event signing
- Event signature verification.
The second two may be protected with threshold structures making them difficult to attack. KERI pre-rotation also protects event signing in the sense that a side channel attack on the signing keys is recoverable via the pre-rotation keys. Event signing is a form of key compromise. The third one event signature verification is the one someone is most likely to take issue with and so should be caveated. One can attack someone’s event signing infrastructure (code) and fool someone into believing that an invalid signature is a valid signature. But it is difficult to attack everyone’s event signature verification infrastructure in any general way so its not usually a very worthwhile attack. You are attacking the validator not the controller. So usually it is assumed that signature verification just works. So a really world class security expert would take exception with the additional statement “no other other attacks are possible” vs simply saying that all attacks must start with with key compromise. Usually stating that something is impossible is a bad idea. Everything is possible eventually.
(SamMSmith)
**Q: How does KERI guarantee the consistency and security of its logs?
KERI's Key event log (KEL) is a cryptographically verifiable hash chained non-repudiably signed data structure.
(SamMSmith)
**Q: How can it be one solution, fit for all SSI problems?
KERI uses plain old digital signatures from PKI, intentionally, so that it may be truly universally applied. KERI solves that hard problem of PKI, that is, key rotation in a standard way. Without a standard way of addressing key rotation, there is no interoperability between systems, they break when you rotate keys because no one knows how to verify the key rotation was done properly. KERI solves that problem.
(SamMSmith)
*Q: Where would you need something quite different than KERI?
KERI does one thing, it establishes control authority using verifiable portable proofs that are KELs.\
Liveliness
We want fungible trust, that is what KERI provides: fungible trust on key management or key state. It does not provide trust for double spend proofing.
If you need liveliness of fungible value, like cryptocurrencies, you can't use KERI for this.
In KERI we have compact security for the sake of liveliness, which means there is no public ledger with total ordering of state. In KERI after duplicity is detected, you don't trust that identifier anymore.
(@henkvancann)
*Q: Does KERI protect a controller against stupid mistakes?
If a controller of a public identifier has a KEL published and with the same authoritative key pair produces another KEL and does not check it's inconsistent with the first one? No, KERI does not protect against that level of stupidity. By comparison, public ledger based identity systems do protect against this stupidity. (SamMSmith)
***Q: KERI is inventing its own key representation and signature format. Why did you do that?
*(@OR13) argues the following:
In order to share code / we would need shared building blocks. Sidetree is built on JWS / JWK. KERI is inventing its own key representation and signature format. These are the lowest level building blocks, so them being different will prevent a lot of potential code reuse.
In brief these are the reasons:
- the desire to control the entire stack, and not use anyone else's tooling
- DID and VC layers are the appropriate layers for interoperability
- The performance/security goals of KERI drive its design which makes incompatible with Linked Data tooling
***Q: Why did KERI WG decide to reinvent multi-codec?
(@OR13) argues the following:
There was a potential for KERI to align with Ceramic / IPFS / IPLD, but that door closed when the KERI WG decided to reinvent multi-codec.
The desire to control the entire stack, and not use anyone else's tooling
Have a look at the Kid0001Comment Summary for why we needed to divert from multi-codec. Multi-codec may not be such a stable standard to be breaking or abandoning.
Multi-codec is a draft standard, a rather chaotic mix of binary and text-based entries in a crowd-sourced registry/table. Most implementers are doing a subset of the Multi-codec chart anyways, making it even more unstable for interoperability purposes.
To go in further detail why multi-codec can't do for KERI: the length of item not included in encoding table - incompatible structure (Multi-codec assumes enveloped data structure). Moreover we need KERI's compose-ability (via concatenation) for framing events. KID0001comment explains in detail why compose-ability is so important and why Multi-codec is therefore not usable.
DID and VC layers are the appropriate layers for interoperability
- streaming support > interop at signature layer?
The performance/security goals of KERI drive its design which makes incompatible with Linked Data tooling
KERI can't use enveloped data formats:
- enveloped data format -> signatures have to put on/outside the payload
- MsgPack and CBOR-> work with block-delimited structures
- JWS/JWK - also enveloped, also incompatible with streaming
- framing events = better streaming support (@bycaballero and@henkvancann_)
*Q: Will KERI be interoperable with DID:peer and Sidetree?
You can implement did;peer and Sidetree with KERI but we can’t implement KERI with Sidetree or did:peer.
Because KERI operates on a lower level.
If we were to do that, we have to tunnel KERI identifiers to create corresponding Ledger-entries.
(SamMSmith)
***Q: Will KERI be interoperable with DID:peer and Sidetree?
(@OR13) argues the following:
Afaik this ship sailed when KERI decided to define its own event format. I don't think KERI shares any commonality with sidetree or did peer, and it's no longer possible to align them, so while you can start with the same key material, doing similar operations will very quickly result in totally different event structures.
I don't see a way for KERI events to be used by anything but KERI for now, certainly not Sidetree. In the future did:peer might use KERI events directly, but then did:peer would not be Sidetree compatible
...
The upside is that KERI could be much better than things built on JOSE. The down side is KERI won't be possible to implement with off the shelf JOSE crypto. Having spent a lot of time with linked data, It looks like KERI is setup to feel all the same kind of pain, regarding reinventing the wheel instead of starting with compatibility with JOSE.
...
I predict a few years from now we will have:
- JOSE / JWS / JWK / jose based DIDs\
Multicodec/ IPFS / IPLD / DAG_CBOR / JWS / JWK / ipld based DIDs\- Linked Data / JSON-LD / CBOR-LD / linked data based DIDs\
- KERI / KERI keys / KERI signatures / keri event log based DIDs
There will be some overlap, for example KERI based DID Documents will likely support JWKs if they want to be useful with any legacy system, but internally KERI will use a different key representation. Similarly sidetree based DIDs will likely support linked data proofs but will only rely on JWS / JWK for internal operations.
As far as I know, the KERI design has specifically chosen not to build on JOSE, IPLD. or JSON-LD / CBOR-LD. So there won't be any opportunity for interop with KERI below the DID Document layer. Which is true of many other systems, including Ethereum, Bitcoin, Hyperledger based DIDs. Many of which don't share event log interoperability.
Imo, if KERI used IPLD / JSON-LD / CBOR-LD, it would be better. Because not using them means reinventing the parts of them that are needed... which comes with the potential for better performance at the cost of inventing a faster wheel, and failing to pull developers / tooling from those established communities. However I can understand the desire to control the entire stack, and not use anyone else's tooling.
From an engineering management and interoperability perspective, I would have decided to break compatibility after the whole system was built and working, and only in the areas where JWS / JWK or IPLD performance, documentation or library support was so bad it was justified.
... We should target interop between KERI and Sidetree at the DID Core and VC Data Model layer.
End of (@OR13)'s plea.
The answer to why KERI is incompatible with Linked-Data tooling
Linked-data is an adoption dead end. KERI believes that immutable JSON Schema are a better solution than mutable schema.org schema. And that when and if backend semantic inference is useful that Labeled Property Graphs (LPG) are a more powerful, easier to use, and more adoptable (already more adopted) alternative to RDF graphs.
Linked data is a euphemism for the semantic web, which, considering how much effort went into it early on, has proven to be a failure. Encumbering VCs with linked data is a failure waiting to happen (for both technical and adoption reasons) especially when there are much better alternatives.
For more detail, read the VC Spec Enhancement Proposal
(SamMSmith)
**Q: How does KERI keep identifiers secure?
By the mechanism of availability, consistency, and duplicity.
We have to handle race conditions too, just like any other distributed database or blockchain.
(SamMSmith)
**Q: How does KERI scale safely without comprising the security model
Safe scaling: is everything more secure as more witnesses and more watchers are added?
Watchers and witnesses have two separate effects:
- Ambient verifiable requires even distribution (and total coverage) of watchers to detect duplicity; the more, the better
- Enough watchers allow a lower threshold of witnesses that need to stay honest - each controller sets a ratio of witnesses that need to confirm an event, if each of the witnesses is watched enough, the security model is the same (and not improved by more witnesses total) (SamMSmith)
These two effects have distinctive security characteristic because for 2. the added benefit of an extra witness decrements with every next witness. On the other hand adding watchers in 1. will create a fixed marginal security improvement with every extra watcher.
(@henkvancann)
Controllers' security increased by more witnesses; validator's assurance is increased by more watchers.
Controllers needs to do an eclipse attack to fool a validator, which is impossibly expensive with enough watchers
(SamMSmith)
Put another way, first few witnesses are exponentially more secure than n-1, but after a few witnesses, each additional witness's security gain approaches zero asymptotically.
(@Chunningham)
**Q: Is the KERL technically a blockchain/hashed data log, rather than a ledger that implies a balance?
Yes a KEL/KERL is a hash chained data structure. But not merely hash chained but also signed, so it's also a cryptographic proof of key state.
It's not tracking balance, it's tracking key state.
(SamMSmith)
**Q: According to the SSI Book KERI will never be able to substitute the internet conventional PKI infra. Right?
SSI Book: "As powerful as this (read KERI-like) solution appears, completely self-certifying identifiers have one major Achilles heel: the controller’s identifier needs to change every time the public key is rotated. As we will explain further in chapter 10 on decentralized key management, key rotation—switching from one public/private key pair to a different one—is a fundamental security best practice in all types of PKI. Thus the inability for self-certifying identifiers alone to support key rotation has effectively prevented their adoption as an alternative to conventional PKI.
| TBW prio 1 |
**Q: How are KERI witnesses and watchers incentivized to spread KELs and KERLs and make them available?
DNS and other infrastructure generally not billed to end-user; relative cost per end-user substantially lower than traditional/first-gen DLTs and blockchains.
An assumption we make: Watchers will be comparatively cheap and small communities, networks, and services will likely stand one up as a "loss leader".
Controllers are incentivized to spin up witnesses. Controllers will likely buy/lease at least 1 witness if they want their AID publishized/diseminated. This is cloud-scale infra (2 orders of magnitude lower than DLT infra).
(SamMSmith)
**Q: KERI versus Lightning/BTC Layer2: could witnesses and watchers form tiers or "layers"? Will there be cheap secondary/lightning-node witnesses and heavy-duty, enterprise-scale witnesses?
Communities and networks will pool resources and security and service models will evolve, we assume. (SamMSmith)
Freer market closer to blockchain market model or pay-as-you-go clouds; no real moats or lock-ins in the spec as written... Implementation guide should maybe go into how to firewall different clients (like virtual machines on a cloud server) or other security-model eccentricities. (@Chunningham)
*Q: Can a conformance test enforce publication of records or logs to judge them fairly as service providers? (@bumblefudge*)
Maybe but that's layers above the current spec. This spec gives anchors for that kind of tracking, at least? //credit scoring based on opaque algos and unknown data stores and local identifiers - nothing portable to audit, proprietary turtles all the way down.
Decentralizing REPUTATION was a core driver of decentralized identity in its early days (and core ideological thread in IIW); we could be dogfooding our own decentralized infrastructure reputation; pagerank and star-ranking systems are opaque and difficult to audit; publishing algos should still be our goal, and auditable algos is everything. (SamMSmith)
**Q: Could a KEL or KERL be pruned or chard-ed?
Compared to blockchains KEL and KERL are lean and mean data structures. So pruning or chard-ing might not be necessary.
KEL and KERL are chard-ed by nature: as soon as delegation comes in or key rotation.
Every KEL is already shard-able because each root identifier could be split, combined, moved whenever (@Chunningham)
Sharding = re-combination of P2P replication (@bumblefudge)
**Q How big is KEL in the worst case scenario or corner case?
You could chunk or prune huge KERLs; that's overkill unless it's really huge You can archive the old state and just keep genesis and last year's updates, for ex.
WCS: high-volume millions of SIGNING events per hour is realistic corner case to worry about, however. If each transaction is sealed as a distinct event, that would make for a pretty big KEL.
That might be kind of an anti-pattern though; implementation guide should probably recommend a Merkle every minute in super high-volume signing infrastructures, for example:
- WCS KELs are 500bytes per event
- 10-30K transactions per second = "visa scale"; load balancing may be needed; horizontal scalability achieved by delegation trees; delegations allow segmentation of storage (i.e. pre-sharding); if audit logs are anchored to delegated events in a pre-shard-ed log, you achieve very good scalability
**Q: Why does KERI demand signing and digesting the full over-the-wire serialization of a message?
The discussion of KERIs approach to serializing messages and signing and digesting the full over-the-wire serialization is inconvenient for implementers. The motivation for this approach I am calling Zero Message Malleability as a property of KERI.
This is a "best practices" security first approach that prevents semantic leakage over time that becomes a transaction malleability vulnerability. Indeed KERI approach trades off some inconvenience in serialization for better security and reduces the inconvenience of needed to have tightly specified semantics to prevent transaction malleability.
(SamMSmith)
**Q: If the KERI resolver "relies on a distributed hash table (DHT) algorithm .. such as IPFS or GNUnet", isn't that a huge contradiction in terms?
If KERI has this built-in reliance, then doesn't that contradict and defeat the whole purpose of KERI?
KERI resolver - due to the KERI architecture we get rid of the "magic box" in a way that I don't have to trust any infrastructure component. DHT is just example how this can be done in decentralized fashion.
But the point is that I don't have to trust any node or network that the statement is correct. I can cryptographically verify that every time with KERI. Compare to current DID infrastructure where I have to trust resolution process in each DID-method because as soon as would get DID Document, I can't verify that this is the correct one. Think of it like DID:peer where I can always be 100% sure that the DDO which I have belongs to that DID. Not every DID method has this kind of properties. And I think this characteristic is crucial for adoption of DIDs.
(RobertMitwicki)
**Q: Delegations in many systems are unilateral. KERI has cooperative delegation. What is that and why is it better?
In many system unilateral delegation is a single point of failure. if a delegated key's delegator gets compromised, you have no way to recover.
Keys are in different infrastructures in KERI. Both the delegator and the delegatee have keys they manage. If one of them get compromised or lost, we still can recover. Each level of delegation allows delegation of the level above.
(@henkvancann)
*Q: Did the simplification ofDelegated Events using Hetero Attachments* come at any cost?
In short, no.
The Issue around simplification of Delegated Events using Hetero Attachments has been created in May 2021. Since delegated KELs were cross anchored, we loosened that to the same way non-delegated events do it: an idempotent authorization from one event log to the other. Delegated events have to go down this path too, whether they're cross anchored or not. And the cross anchoring has a dead-lock risk, so we wanted to get rid of that. The advantage of not having performance risk on blocked processes on both event logs is huge. All the attacks that we (in a validator role, ed.) could think of, were still protected by duplicity detection. So using the same duplicity detection mechanism they use for non-delegated events, they're still protected for delegated events when they're trying to validate them (the latter, ed.). Since they have to do it for non-delegated events, the additional security of a cross anchor doesn't change their code. The validators still have to going to do it the hard way for non-delegated events, so removing the extra security for a delegated event, didn't do anything. Relaxing the original cross anchoring, doesn't hurt us in any way.
The only thing I was worried about is whether we were still able to recover pre-rotated keys in a delegate, that that kept working the same way as before the simplification. And after my round of testing, it did.
So the simplification does not come at a cost, it's an outright improvement because we got rid of the cross anchoring.
(SamMSmith)\
To be idempotent, clients can make that same call repeatedly while producing the same result.
Q&A section Identifiers
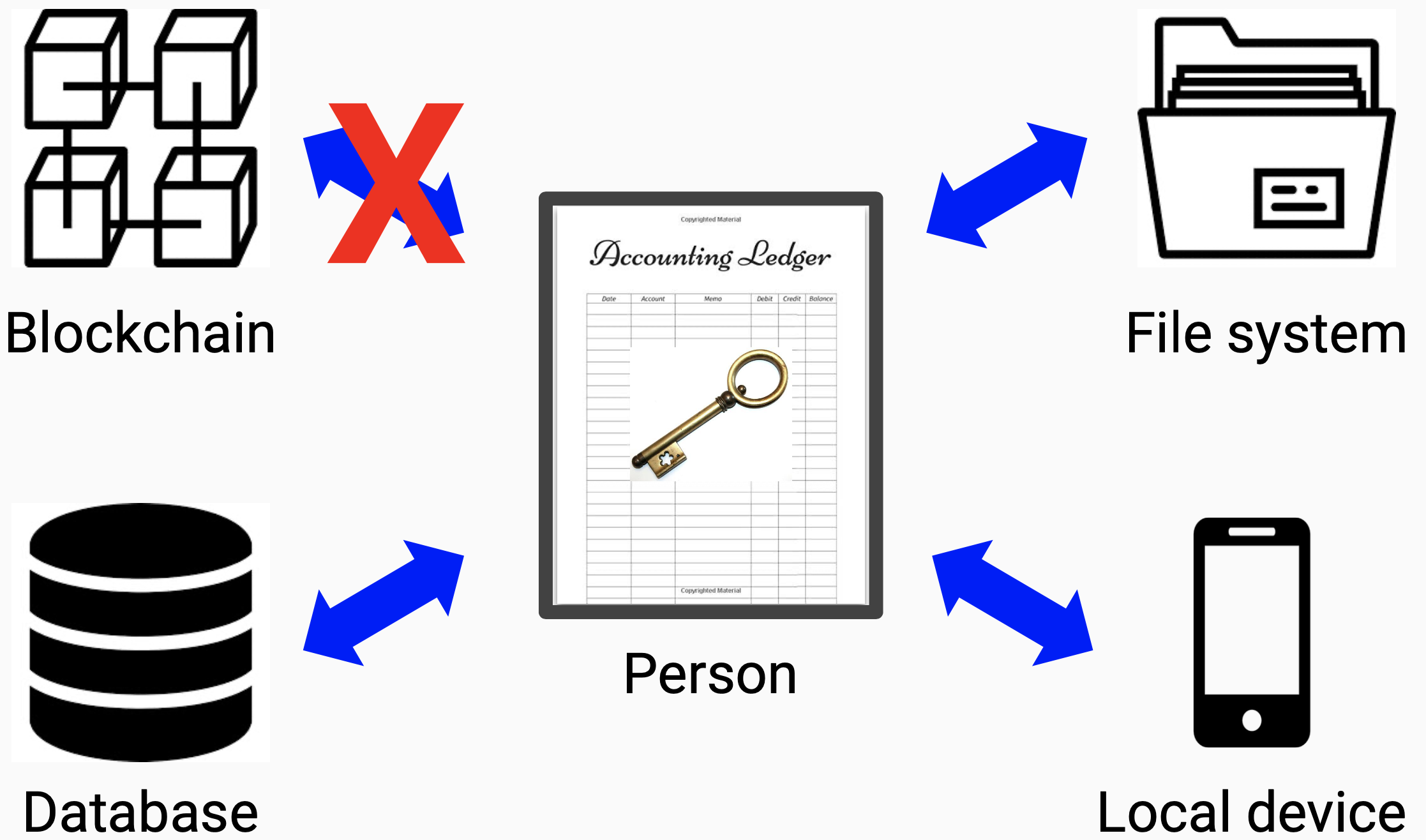
*Q: All you need is a secret key that underlies your entire online identity?
More precisely put you need a Public Private key pair of which the private key is kept secret. Merely a secret key is not good enough. It must be PKI. KERI is a new take on PKI that fixes the flaws in existing PKI systems without needing blockchain as a crutch.
(SamMSmith)\
Missing a point
Why not? One way function(s) in PKI derive the Public key(s), so in my understanding a secret key with sufficient entropy is the start of it all. Where do I miss a point?
SamMSmith:
Yes, you're mission a point. You can use secret keys with symmetric cryptographic operations. Both asymmetric and symmetric start with a secret key but asymmetric goes on to create a public private key pair. So its not only a secret key you need but one that results in a SCID. Someone who is used to symmetric cryptography would get the wrong impression.
**Q: How is a KERI identifier different than a regular identifier in DID methods?
A self-sovereign identifier that is not self-certifying is dependent of infrastructure and is not fully autonomous and not fully portable. KERI uses autonomic identifiers, fully cryptographically derivable and portable. (@henkvancann)
*Q: Is my KERI identifier public?
In the direct mode (peer to peer) KERI can be used to keep identifiers private to the peers or group involved. In the indirect mode all identifiers are public. The privacy of the individual, group or object described by the identifier is weak because anyone can bind and identifier to a subject anytime and anywhere. Fortunately, this binding is weak too, As soon as controllers and verifiers sign statements / events related to an identifier, that's when the binding gets strong and subjects publicly exposed.
(@henkvancann)
**Q: Is a KERI identifier GDPR proof?
KERI enables support for protection against liability that could stem from gdpr’s right to be forgotten (passive approach) and the right of erasure (active approach). There are two exceptions to the general rule that you have to remove an identifier from your database, if a subject and / or controller requests so:
- As long as you're a party in a transaction involving the identifier that has been revoked, then you can keep that identifier in your log.
- For archival integrity - given that KERI’s whole reason for existence is keep track of duplicity in identity events it is important to know that an identifier has been erased before, because we don't lose that notion. Because somebody could come up with the same identifier in the future and we wouldn't know that it existed before.
Within the assumption of both exceptions KERI complies with the GDPR rules:
- block-list of “deleted” KELs: a receipt of a request for erasure must naturally hold some PII, a two-party interaction might allow this to be recorded.
- a need to maintain system integrity/archival purposes can be a reason for maintaining some info right of erasure versus right to be forgotten. This active and passive approach reflects two slightly different interpretations of the same article (which one people use is a hint of their school of thought).
Beware that most of GDPR rules are there to protect you from being exploited. So you're not being prosecuted or being labelled as a criminal activity. It might only be illegal and somebody could hold you liable for that. (@henkvancann)
*Q: What do I need a self-certifying identifier for?
It is a cryptographically derived, strong binding between a controller, a key pair and an identifier. No weak bindings introduced by administration present. (@henkvancann)
**Q: How does self addressing work for the identifier?
Using a content digest not only binds the inception statement to the identifier but also makes it easy to use the identifier prefix to retrieve the inception statement from a content addressable database.
Mechanism:
**inception statement -> hashing -> #**
# points to a record in a database:
**# -> inception statement -> hashing -> # (proof of "address")**
This requires that the database store the signature with the inception data, so that a reader may cryptographically verify that the inception data is authoritative. Without the signature the digest is repudiable by the controller. This approach also enables content or document specific but self-certifying identifiers.
inception statement -> sig + derivation + public key + extra data
Check sig with public key ->
non-repudiable unique attribution to the content by whoever controls the private key
*Q: What do I need a self-addressing identifier for?
In brief:
- commitment: non-repudiable unique attribution to the content creator as controller
- confidentiality: a decryption key must be obtained from the controller
Self-addressing identifiers provide a mechanism for a content addressable database to enforce non-repudiable unique attribution to the content creator as controller. This binds the content to the creator in the content address. Different creator means different address. This makes confidential (encrypted) content more usable as the content address is bound to the controller from whom a decryption key must be obtained.
***Q How can I prevent a direct mode interaction being published and breach a controller's privacy?
The assumption is that direct mode is meant to be private communication.
- There is understanding when you use direct mode that it needs to stay private
- There is a possibility to impose a liability, under consent at the time of issuance
- There is no way to enforce the KEL from being kept private
**Q: What is tombstoning and could it help to preserve privacy of identifiers in KERI?
Tombstoning in Self Sov Identity and DIDs has a very different meaning than in everyday's language (where it means 'the act of jumping in a straight, upright vertical posture into the sea or other body of water from a high jumping platform, such as a cliff, bridge or harbour edge.')
It stems from the development of ledger-based identities like Sovrin. Tombstoning means "Burry the transactions" Because Sovrin is a permission-ed ledger, the steward lets you read it - or won't let you read the transactions, depending of the situation whether the subject of the personal information has requested to be forgotten. A steward could say 'see, I've not published the personal information, so I am good.'.
For other reasons, tombstoning has never been accepted as a viable solution to get rid of the liability issue.
Tombstoning does not apply to KERI because in indirect mode KEL and KERLs will be ambient available and in direct mode their are only to parties involved. If a third party would be involved in direct mode, somebody would breach the understanding that it's private communication by design. (@henkvancann)
*Q: What do I need a multi-sig self-addressing identifier for?
To get even more security in terms of your signing scheme.
(SamMSmith)
**Q: What do I need a delegated self-addressing identifier for?
To be able to horizontally scale your identifier system, that consists of a root identifier that manages a bunch of other delegated identifier. Created with a cryptographically derived strong binding, all the way through your infrastructure. Not dependent on any administration at all.
(SamMSmith)
*Q: What do I need a self-signing identifier for?
Often it is an efficiency measure where the identifier includes the signature as your content-addressable hash.
(SamMSmith)
**Q: What do I need a non-transferable identifier for, as KERI supports transferable identifiers?
Its use is different. Many applications of self-certifying identifiers only require temporary use after which the identifier is abandoned. These are called ephemeral identifiers. Other applications may only attach a limited amount of value to the identifier such that replacing the identifier is not onerous.
Because a non-transferable (ephemeral) identifier is not recoverable in the event of compromise, the only recourse is to replace the identifier with another identifier. In some applications this may be preferable, given the comparable simplicity of maintaining key state.
In either of these cases a non-transferable self-certifying identifier is sufficient.
**Q: Could you give an example of solely a cryptographically verifiable inception statement
This is a basic self certifying identifier (SCI). The identifier itself is derived from a public key that is in the identifier. Nothing is connecting that binding of the identifier to the inception statement. Someone could create an different inception statement with other fields, the only thing that need to be the same is the key list. Everything else in the inception statement could be different.
So that means the only way to know which inception statement is the right one is duplicity detection. So First seen becomes the only means you have to check which inception statement is the authoritative for that identifier, in case you need an inception statement.
**Q: Could you give an example of strongly binding the inception statement to the identifier
This a self-addressing self-certifying identifier (SASCI) In this case the identifier itself is derived from the inception statement. Now there can only be one inception statement for this identifier. If you'd change just a single bit, other than the identifier field itself, and it's different identifier. You can't have duplicitous inception statements. It's not possible. It locks down at least the inception part and that help in duplicity detection. There can only be one inception statement to start a duplicity log with. From that point on you can have duplicitous next events, but not before. But it still means the effort it takes has to engage in CreatING duplicity, becomes much harder because for example if you include witnesses in the inception statement then any duplicitous event has to publish through the witnesses, and that adds a barrier. Basically it locks down at least the inception part, You can't change it.
In some cases it would be useful to be able to strongly bind the inception statement to the identifier and not merely rely on a cryptographically verifiable inception statement for the associated identifier.
**Q: Why ever go for a basic self-certifying identifier (SCI) when KERI offers self addressing SCI (SASCI) with a better security guarantee?
Because there are many applications where you don't want to have to depend on a KEL because a basic SCI is self-certifying without a KEL. It's more light-weight. For example the non-transferable version of a SCI you can still have an inception event so that basically any tracking anybody does there is still a nominal KEL for that identifier so you can look it up that way, discovering everything, there is always a legitimate version of an inception event for every identifier.
In many cases you want identifiers that are ephemeral, that you know the only event that could be would be is the inception event. You don't need to see the inception event, if you're using it in an ephemeral context.
E.g. witnesses use ephemeral SCIs so I don't need a key event log for a witness to verify a signature by a witness. You can do that with watchers as well. In applications like IOT where you need light-weight identifiers, you will mostly use SCI (1.). So you would use the basic version.
Want you don't need to do with the basic identifiers is you don't have to say 'I got an identifier but I can't verify the keys before I get the KEL so I don't know the key state'. For the witness there is no key state. There is only ever one key. If the witness is ever compromised, then you get rid of the witness. You can rotate keys or rotate identifiers.
Rotating an identifier is allowing us to change the keys for an ephemeral identifier.
In an ephemeral context rotating the keys is the equivalent to rotating the identifier.\
Example BTC and ETH they are ephemeral public keys, you can't rotate keys in BTC without changing the identifier. You have to move all your funds.
In KERI the closest to 1. is DID:Key. Instead of having multiple DID methods, KERI unifies them all into one protocol.
Look for more info in the KERI slide deck ["KERI for the DIDified"](| TBW | .md).
***Q: Identifiers aren’t self-managing or self-certifying. That’s just not a thing?
Identifiers are managed by systems and humans using systems. Identifiers are not actors. That sort of slippery language is the kind of meaningless hyperbole that borders on disingenuous.
KERI's creator is using semantics from several different disciplines and then making new semantics when there is not a good fit. So it all sound like new semantics. But only a few are truly new to KERI. But since we can't know what the set of new and not new is for any expert exactly, we can't know what to spend more effort on defining vs what to assume. That is why an adaptive discussion works much more efficiently.
**Q: How does a Sybil attack present itself in KERI and what is the damage that can be done
In short: A Sybil in KERI has at most the power of DDOS attack.
KERI distributed hash table (DHT) is most vulnerable to Sybil attacking/corrupting a portion of a table. They can't rewrite the cache so a Sybil attack cannot invalidate KERI, but they can DDOS the pipeline of KELs with invalid KELs so the user never get a valid KEL to process.
KERIdemlia would, for example, be DDOS-able if it were used to index KERI nodes; KERI verifying data before replicating it slows down DHT formation, but keeps the DHT safer from Sybil attacks via user-permission-ing or micro “reputation system”.
Side note: user-permission-ing of watchers is where most of this verification happens at scale
Q&A section Event logs
*Q: What is a Key Event Log?
It's the basis of the source of truth for KERI identifiers. KERI enables cryptographic proof-of-control-authority (provenance) for each identifier. A proof is in the form of an identifier’s key event receipt log (KERL), after a validator verified the registered events, in the chain of events: the key event log (KEL).
(@henkvancann)
*Q: Why is a Key Event Log crucially important?
Without KELs, we wouldn't have a chain of registered and signed key events for an identifier. The availability and consistency of the KEL is crucial for next steps: verification of events and duplicity checks. Without verified KELs there will be no KERL for identifiers at hand.
(@henkvancann)
**Q: How do I create a KEL?
By a key inception event. A controller creates a key pair and binds this to his/her KERI identifier.
There will be wallet software and an API available in the course of code development and also a DID scheme (DID:UN) that invokes calls to those APIs during resolution of the DID.
(@henkvancann)
*Q: How can I trust a KEL?
It is secured by a Distributed Hash Table, so internal inconsistencies are cryptographically provable. If they they are internal consistent the first level of trust is established. Furthermore a KERL is end-verifiable to the root-of-trust. You don't need the whole KERL at all times Read more why.
KEL is considered a secondary root of trust (Whitepaper, Page 60/141, Section 7.35).
(@henkvancann)
**Q: Does the AID together with its KEL acts collectively as the primary root-of-trust?
In brief: the security of an identifier does not start with a KEL, the security starts with entropy.
The exhaustive explanation by Philip Feairheller
It is important to remember that KERI's security is based on the layering of thresholds. The whole is greater than the sum of it's parts. So while it seems that with a transferable identifier (one that can be rotated), the security of the identifier starts with its KEL, it does not.
As with all identifier types (transferable and non-transferable), the security starts with entropy. The randomness used to create the private key is the absolute root of trust. Once you create the private key you retain the ability to prove control over your identifier by your ability to use the private key.
With non-transferable identifiers, it ends there. With transferable identifiers, the next root-of-trust (and thus a secondary root-of-trust) is the KEL which provides the ability to rotate the keys of the identifier. Additional roots-of-trust layered on top of entropy and KELs include multi-sig support, delegation and witnesses.
Q&A section Inconsistency and duplicity
What kind of Inconsistencies do we have?
An internally inconsistent KEL, this simply won't verify. External inconsistency: two versions of the key event log (KEL).
How can it be garantueed than an identifier represents a certain identity and not another one?
KERI takes advantage of its cryptographic root of trust with strong bindings, to get an inviable guarantee, based on both internal consistency for the cryptographic root of trust and external consistency using ambient duplicity detection.
*Q: What is Duplicity?
See the definition. What it means is that we have a way to make judgments about trust in entities.
(@henkvancann)
**Q: What does duplicity look like?
Duplicity takes two forms. In the first form, a controller may be deemed duplicitous whenever it produces an event message that is inconsistent with another event message it previously produced. In the second form, a witness may be deemed duplicitous when it produces an event receipt that is in- consistent with another event receipt it previously produced.
(SamMSmith)
*Q: Why should we care about Duplicity?
Duplicity becomes a basis for distrust in a controller or its witnesses. (SamMSmith)
**Q: What is the main benefit we get from duplicity detection?
Duplicity detection buys validators protection without the need of anything more than a duplicity detection network.
Q&A section Key rotation
*Q: What is Key Rotation?
Changing the key, i.e., replacing it by a new key. The places that use the key or keys derived from it (e.g., authorized keys derived from an identity key, legitimate copies of the identity key, or certificates granted for a key) typically need to be correspondingly updated.
the main purpose of key rotation it to either prevent or recover from a successful compromise of one or more private keys by an exploiter.
Source.
**Q: Why bother about key rotation?
The primary purpose of rotating encryption keys is not to decrease the probability of a key being broken, but to reduce the amount of content encrypted with that key so that the amount of material leaked by a single key compromise is less.
However, for signing keys there is a concrete reason: say it takes X months of computation (expected value given your threat model) to crack a key, and you rotate your signing key every 𝑋−1 months and revoke the old one, then by the time an attacker has cracked the key, any new signatures produced by the attacker will either be A) rejected by clients because of key expiry, or B) back-dated to before the key revocation (which should also raise warning in clients).
Source.
**Q: Why does KERI solve interoperability with its key rotation scheme?
KERI uses plain old digital signatures from PKI, intentionally, so that it may be truly universally applied. KERI solves that hard problem of PKI, that is, key rotation in a standard way. Without a standard way of addressing key rotation, there is no interoperability between systems, they break when you rotate keys because no one knows how to verify the key rotation was done properly. KERI solves that problem.
**Q: What is Pre-rotation?
Pre-rotation is a cryptographic commitment (a hash) to the next private key in the rotation-scheme. (@henkvancann)
The pre-rotation scheme provides secure verifiable rotation that mitigates successful exploit of a given set of signing private keys from a set of (public, private) key-pairs when that exploit happens sometime after its creation and its first use to issue a self-certifying identifier. In other words, it assumes that the private keys remains private until after issuance of the associated identifier.
Source: chapter Pre-rotation in whitepaper
*Q: Why hasn't pre-rotation or forward chaining been done before?
I first wrote about in 2018, it's been public knowledge ever since. I guess people just don't read.
(SamMSmith)
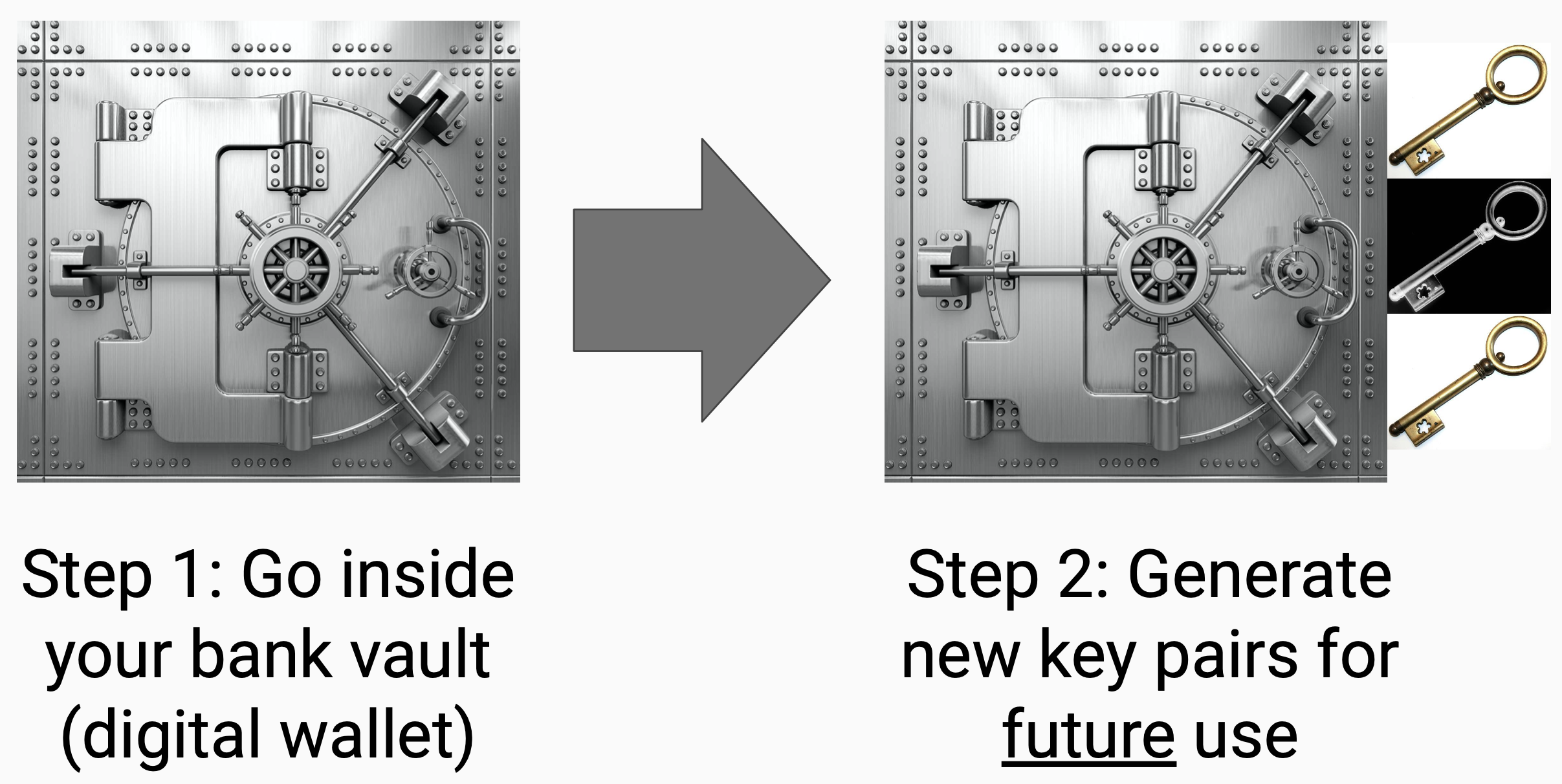
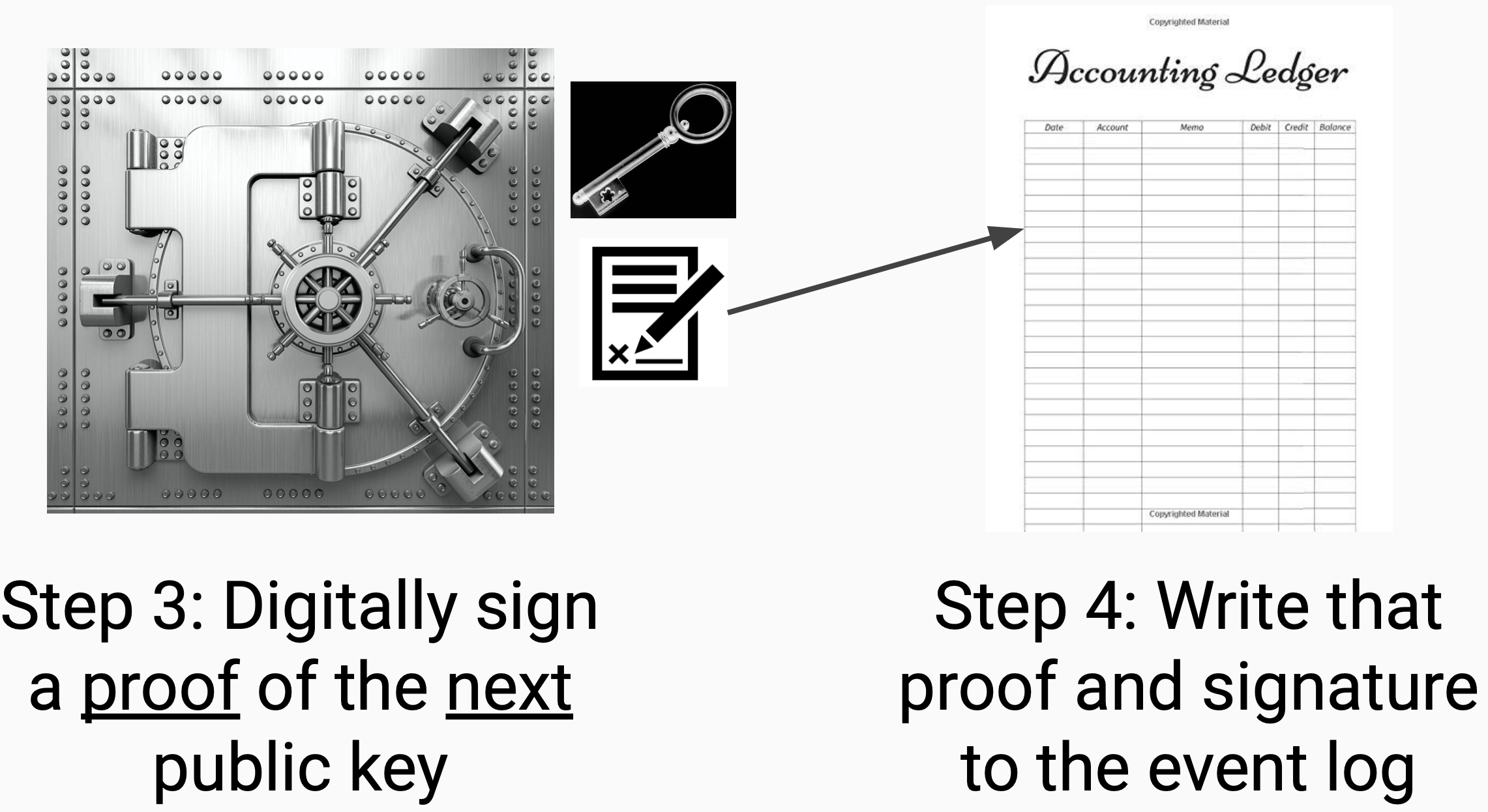
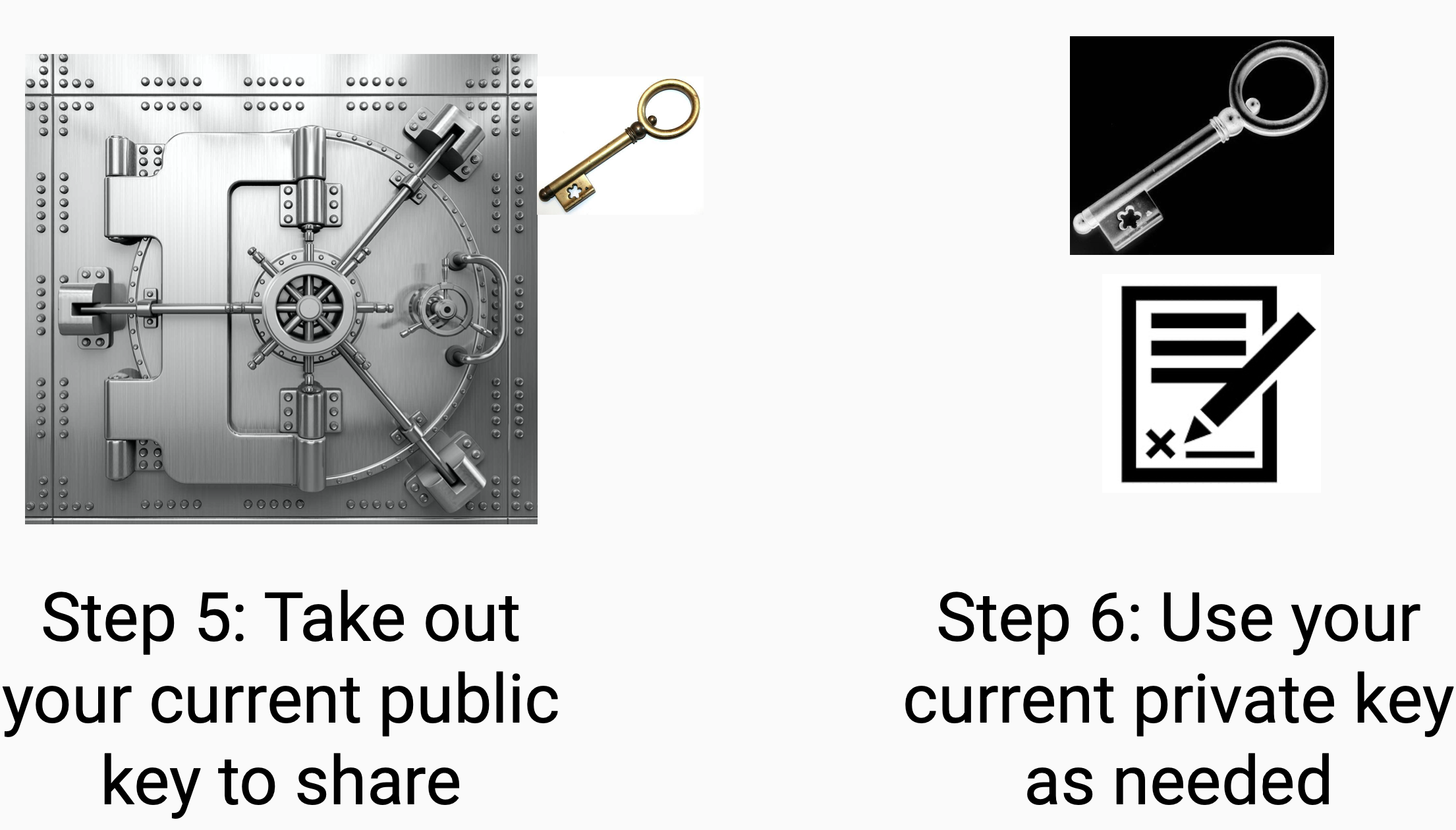
*Q: What do I need to do step by step to rotate my keys?

Q&A section KEL and KERL
**Q What is the difference between KEL and KERL?
The word 'Receipt' explains it all: the sender signs off the verification of the KEL done by the recipient. That Receipt is hosted in the KERL and is the root-of-trust for KERI.\
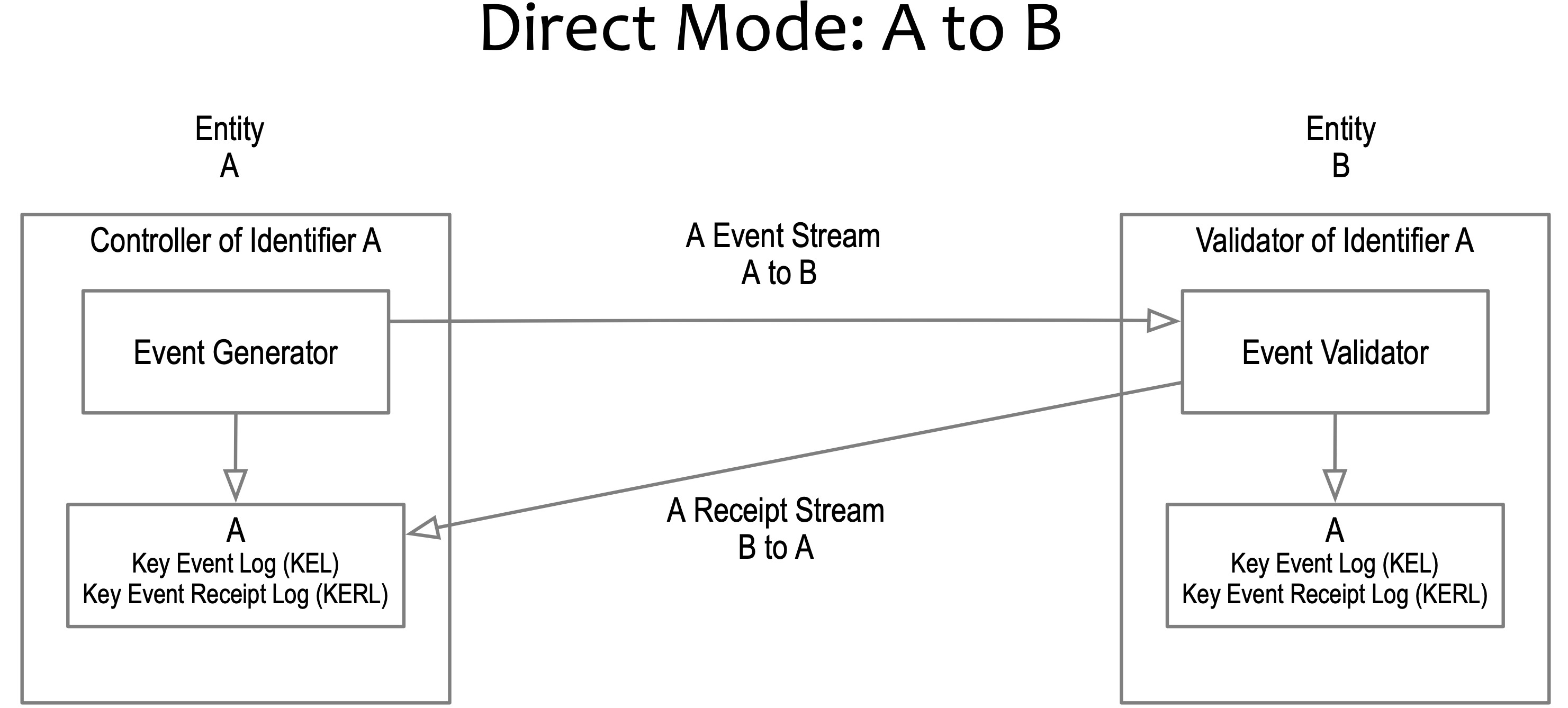
The analogy is the difference between a two-way - and a three-way handshake: Did I, the recipient, only verify that the sender's message was valid (two-way using KEL, arrow left to right) or did the sender sign off the receipt of that verification by the recipient (three-way in KERL, arrow right to left) (@henkvancann)
Can a KEL grow too big, so that performance becomes an issue eventually?
In short, No, KERI has several fall-back options to deal with lingering enlargements of KELs or declining performance, if ever actual. And that is batching and horizontal scaling the issuers.
Supposing we have a big KEL, which means a long chain of hashed data, then there a few relevant features of KELs within KERI:
- A KEL will always be order of magnitude smaller than public blockchains, because they are more specialized structures that do not need to contain total ordering
- Once a KEL has been verified by a user, it can be archived by this user.
- The core key events in KERI like inception, rotation and delegation are worst case still irrelevant to the scale of volume of a KEL.
- The seals of Interaction Events don't need to be put in the KEL one by one, you could put a whole bunch of Transaction-seals in a sparse Merkle tree and only register the Merkle root in the KEL.
- Private KEL are small per design, because in private interactions the identifier have no public value attached to them
- Public KEL can be associated with public entities like humans, organizations and devices and therefore accumulate value on the identifier through interactions.
- For security guarantee there is no difference between a big KEL and a small KEL. Both need to be internally consistent and verifiable to the root-of-trust.
- We have the opportunity to create delegated identifiers and delegate KELs. So a big KEL is a long KEL and has the features just described.
Now suppose a KEL of a long-lived public identifier gets too big, even if that is not very likely to happen. Then what are our options?
- Create a new identifier, do a new association (or binding) to a public entity and spread the news in a reputational way. Abandon the old identifier but keep it live for future verifications of old events.
- You can create a set of delegate KELs and issue verifiable credentials from those delegates. And load balance the size of your KELs by the number of delegates you introduce. And they all verify back to the same root-of-trust of the delegating identifier. Optional:
- Gather all Interaction events of the old KEL, which starts to grow too big, in a batch and anchor with a single Merkle-root hash to the new identifier
(@henkvancann) based on IIW32 recording of session KERI: Centralized Registry with Decentralized Control (KEL & TEL ) + DEMO\
Q&A section Witness
**Q: What's the urgency of replacing a witness once duplicity is detected?
Looking at a certain identifier and controller, does the witness service, representing the controller, need to be replaced once duplicity is detected? For example after a dead key attack?
No. The service can be the same. KERI includes a cryptographic commitment to the identifiers of the nodes in the service. The compromised controller will have its own nodes and service but they are not the same as the original ones. As soon as you have a compromised controller than you also have a duplicitous service. For a validator to back up his choice of which service to choose is not hard, because it can be easily verified which service belongs to the original KEL.
**Q: Witnesses have no skin in the game, it’s a nothing at stake situation, no?
The KERI slide deck has a section called the Duplicity Game. I suggest reading through that first. Or see the part of the SSI Meetup webinar that tackles this.
(SamMSmith)
| TBW prio 2 |
***Q: What is the difference between Key Event Receipt Infrastructure (KERI), and distributed hash tables (DHTs)?
The data structures behind KERI are a special form of DHTs, but KERI is more than that (non-exhaustive list):
- a solid key management protocol
- verifiable DHT to the root-of-trust
- a direct and an indirect method of interaction about key event state
- duplicity detection
- various recovery mechanisms from duplicity, key loss or key compromise
**Q: As long as witnesses keep lying together no one will ever be able to prove them wrong?
Witnesses do not make any statement about the content of what is being proved. KERI does not enable someone to proof the veracity of a statement only the authenticity of the statement.
(SamMSmith)
This is a very crucial concept in KERI: Authenticity first, plus the stingent division of making sure who said it and whether what was said is true or false. The former is in KERI verifiable to the root of trust, which is a killer app compared to current the state of internet. The latter, finding out if someone speaks the truth, is not cryptographically verifiable; the veracity of a statement can only be attested (credentials) and weighed.
(@henkvancann)
***Q: Why does the Witness run in restricted mode?
It’s not "first seen" until it’s fully seen by the whole set of witnesses needed (threshold). In the meanwhile the witness in this instance, has to add an escrow. And wait for the witness receipts coming in. And then accept the KEL. (@henkvancann)
***Q: The Round Robin in indirect mode is more efficient than gossiping?
Yes. It has _complexity where as gossiping has the more "expensive"nlogn complexity. However, Round Robin has the characteristic of building up latency, which can be a burden in speed-sensitive use cases. A provision has been planned in KERI to offer best of both worlds.
(@henkvancann)
*Q: What does 'fully witnessed" mean?
It means that the threshold of the number of witnesses has been met, It doesn't mean that all witnesses have witnessed the event.
***Q: So what if a controller rotates 100% of the witnesses out?
| TBW, just soundbites from the meeting KERI WG April 6 2021 listed below | This is an extreme corner case. There is an additional requirement to add to the key state.
In this situation a validator can't find the witnesses. Then they have to bootstrap from a new set of witnesses.
The previous witness set needs to be able to (to have the add and remove list).
It's a bridge, it's a forwarding service and is a temporary provision, until all the validators have seen the more recent key state. Witnesses witness an event that rotates them out. They don't sign the rotation event itself. It doesn't have to contribute to the first seen. It will be included in the key event log at the end of it.
The Witness will provide meta data for how long it will keep up the forwarding service if it will become rotated out. The pull of the event by the validator has to be more frequent than that given time per witness that it will keep the forwarding service up & running.
**Q: Which trade-off is there for the validator?
This is listed as an option in the white paper:
The validator can include what he/she considers first seen: the previous set of witness AND the current set of witnesses (after rotation) has to be fully signed. This makes it extremely difficult to perform a dead key attack (eclipse attack).
The backside of this is that more and more controllers will become duplicitous as the requirements on first seen are so strong.
*Q: What is KAACE?
The primary purpose of the KA2CE algorithm is to protect the controller’s ability to promulgate the authoritative copy of its key event history despite external attack. This includes maintaining a sufficient degree of availability such that any validator may obtain an authoritative copy on demand.
**Q: Each DLT has a strategy that has been vetted and tested, often with billions of dollars at stake. With KERI, the witness strategy seems disturbingly variable?
The witness strategy is variable by design. To which extend this disturbs depends on assertions.
KERI doesn't give similar guarantees then a DLT. For an identifier system you don't need all that a DLT gives, you can do an identifier system without a DLT. All you need is what KERI gives. And then we define what KERI gives both the similarities and the dissimilarities in excruciating detail. And it is not true that a witness structure must do what a DLT does. It's much much simpler, which has been explained here. (SamMSmith)
Q&A section Watchers
*Q: How can we detect duplicity? Suppose controller has power over witnesses
In a Public setting duplicity detection protects the validator from any duplicity on the part of the controller and any resources such as witness that are controlled by the controller.
Since a given controller in a public setting may not know who all a given validator is using for duplicity detection (watchers etc), the controller can't ensure that they will not be detected. And once detected any value that their public identifier had is now imperiled because any entity with both copies can proof irrefutably to any other entity that the controller is duplicitous (i.e. not trustable).
(SamMSmith)
**Q: Do Witness/Validator systems introduce a trusted intermediary layer?
and introduce a centralized set of Location Providers, who you must trust to be nice and let you hop to another Location?
Your witnesses in KERI are not under the control of any intermediary per definition. It’s a choice. And this choice is to be made by the controller. KERI is globally observable because its ambient availability. A validator gets the signal from duplicity detection. And then the controller could indicate what’s going on (if the controller is not malicious of course).
This how a validator can reconcile with a fallback mechanism (eg. key rotation). KERI does not guarantee liveness of the key state (example where you have liveliness of key compromise: a btc address and its authoritative key).
Instead, KERI is a key compromise discovery mechanism. And if there is a compromise, you can send a signal. KERI is all about end verifiability of digital signatures. Digital signatures are legal contracts and it's dependent on the ecosystem governance framework how to avoid liability of the controller for the right key state. KERI does not answer that question. The liable controller can add on several layers in / with KERI to reduce the risk of the controllers liability. The risk that successful attacks can occur, can be diminished because they can add extra protection mechanisms.
*Q: What is the scenario for a Verifier to check the key status?
A verifier that gets a VC checks the issuer. with the public key.
So it's approximately equivalent to resolving a DID in most cases.
(CharlesCunningham)and(RobertMitwicki)
*Q: What is the scenario for a Verifier to check the key status?
KERI has a content centric approach: it's what we get and not where we get it. So as soon as you have the KEL (get it from anywhere, what matters is the consistency of that log. The public key is stored in the KEL.
*Q What’s the difference between a Watcher and a Juror
Both are validators. Jurors report duplicity, validators won’t.
Q&A KERI and blockchain settled DIDs
***Q: Is it possible to create a KERI DID that is permanently locked to the "did:key" style / ephemeral?
It is. Sections 2.2.3 - 2.3.1 of the white paper explains transferability and the "basic"-type identifier, which always represents a public key and may be either transferrable (can be updated) or non-transferrable (ephemeral/did:key style). section 14.2 actually details how these are encoded, basically check the first few chars of the identifier.
(CharlesCunningham)
***Q: DID data model supports verification methods which are not based on public keys or even any cryptography at all. KERI can't do this?
In many ways KERI is "better" than DIDs, especially when it comes to proof-of-control. But I think this is one thing that DIDs can do that KERI can't: verification methods which are not based on public keys or even any cryptography at all.
KERI can support them, with some special event type, they use it to store CRDT ops.
(@OR13b)
The point of KERI is to maintain to control of key-derived identifiers. It's not intended to provide all the capabilities of DID.
(@_stevetodd)
***Q: Is it fair to say that DID resolution in general is a security weakness and then push forward KERI in that name?
Although some DIDs have not kept up with design goals of DIDs, e.g. did:web, it is too strong to state this in general. It simply depends on the DID method?
decentralization, persistence, cryptographic verifiability.
In brief: we argue that the chain is as strong as its weakest ring.
Security is not build into the protocol but indeed as the elaborate question mentions, it depends on the DID method. Which overall is a huge risk for community as people needs to know the security level which each did method brings. From that perspective without unified security model brings us to the similar situation where, me having private email server in the basement to avoid spying by google, I send out my e-mail to you having it on gmail. I have high security and privacy but other side have just security without privacy. The outcome is that security model is applied in wrong place and KERI aims to fix it.
(RobertMitwicki)
***Q: Because the DID data model theoretically allows DID methods and verification methods that may NOT be based on cryptographic keys, KERI is capable of spanning all DIDs?
We would like to see some examples of verification methods that are not based on cryptographic keys and are in the scope of DID. The KERI community would like to learn more about these methods. It's true KERI is all about cryptographic commitment. But KERI can also support hashed based identifiers e.g. a fingerprint of the content as unique identifier, without the control part.
***Q: How do I find all the DIDs that stand for apps, code modules, public businesses, and other entities that benefit from being publicly discoverable on a decentralized deterministically iterable registry?
How might one build a decentralized deterministically iterable registry for such use cases where the entries are securely known to be from the matching Identifier?
The reason I am asking is to get people to think about the system they'd inevitably need to create to support the 95% of use cases (given 95% of identity interactions are between personas of people, places, and things that are discoverable)
Is it not a helpful exercise to game out the things required to support 95% of DID use cases with other DID system developers?
It's considered a privacy property of KERI, that you cannot enumerate all identities, in the same way that finding all minorities of certain religious preference might not be a feature.
(@OR13b)
Discovery is a layer on top of what KERI provides. KERI doesn't preclude DID, nor does it need to implement all of DID. KERI will participate in the DID ecosystem. (@_stevetodd)
It doesn't need/want to solve/serve that slice of the use case pie.
**Q: Follow up question 1: Why does KERI rule out 95% of the DID-based use cases upfront, where we need public discoverability on a decentralized deterministically iterable registry?
The vast majority of users use apps and services that are exchanges between or about the well-known,
publicly resolvable registered persona DIDs of people, places, or things?\
Let's list a few to see how much of human digital life it covers:
* All social media: Twitter, Facebook, Instagram, Telegram, Signal, etc.
* All public content creation: YouTube, SoundCloud, Spotify, etc.
* All current registries: NPM, all app stores, all things that use those registries
(basically every piece of software on the planet)
* All publicly registered objects: cars, boats, airplanes, etc.
Put it this way: very few use cases on this planet will not directly, or within them,
rely on publicly iterable, globally registered persona DIDs.
But that said, I'm interested in hearing other opinions or counter arguments to the contrary.
(_@csuwildcat_)
There is an implicit need for the registry to track its entries as DIDs. I guess those 95% use cases will have to get other types of DIDs for that?
It's possible to make a DID doc that represents a KERI identifier. If you want to resolve it, you can put it in any number of blockchains. That just publishes it. However, they don't have to be published to work.
(@_stevetodd)
Or for example TOR hidden services, these are not designed to be discoverable. In fact, the whole point of tool is to provide anonymity. Anonymity is a property of set membership, and it's destroyed by making the sets small or enumerable. (@OR13b)
In many scenarios, what the elaborate question explains makes sense. I can understand a different design goal/priority for KERI, I think the rationale is quite clear in terms of where it stands in the DID space. (@fimbault)
**Q: Follow up question 2: That's not deterministic?
You can't have Registry A magically just trust that a DID from Other System B, it would need to be native to it?
Any registry with deterministically resolvable entries requires the entry controllers' IDs and resolutions be native to it. That's an empirical computer science wall type of requirement.
Imagine I want to register a DID in a decentralized deterministically iterable registry - something anyone can run and deterministically know all entries registered with it, wherein the registry has no central entities or authorities that determine the bindings between entries and those who control them...\
Nowhere in any paper on this planet is this a solved problem, because it's basically NP hard
It depends on what you mean by resolve. The white paper explains the points brought up in this question. (@_stevetodd)
| TBW prio 1 |
**Q : Nowhere in any paper on this planet is this a solved problem, because it's basically NP hard
It's considered a privacy property of KERI, that you cannot enumerate all identities.
(@Or13)
Q&A Security Guarantees
**Q: What are the security risks of KERI with regard to the identity protocol?
Harm that can be done to the a controller: Unavailability, loss of control authority, externally forced duplicity
Harm that can be done to a validator: Inadvertent acceptance of verifiable - but forged or duplicitous events.
Breaking the promise of global consistency by a controller is a provable liability. However, global consistency may only matter after members of that community need to interact, not before.
(SamMSmith)
*Q: How secure is the KERI infrastructure?
KERI changes the discussion about security. From a discussion about the security of infrastructure to a discussion about the security of your key management infrastructure. Most people when they think security, the think "oh, blockchain!": permission-ed or permission-less, how hard is it to get 51% attack, etc.Non of that matters for KERI. KERI is all about "are your private keys private?!" And if yes, that drastically slims down the security discussion to brute force attacks to public keys. And because the next public keys are in fact protected by a hash, you have to brute force the hash algorithm, that is post-quantum secure. So that is a very high level of infrastructural security.
So private key management and protection is the root of your security in KERI.
**Q: Can I rotate keys with Tangem in KERI?
Suppose I'd trust a Tangem card for generating public private key pairs at will and the NFC communication allowing to interact with a wallet app.
One of the main concerns is that there is a theoretical link (a binding) between the cards and a user, via the card-ID (CID). However the CID is used only for checking the authenticity and integrity of the chip itself. Tangem publishes and anchors a list of CIDs with corresponding public addresses in a public blockchain. When checking authenticity, the verifier looks up the pub CID and corresponding pub address in the published list, and verifies that the chip controls the correct pub address by means of a challenge-response scheme. Even though for blockchain or SSI interactions, a completely new wallet with new pub/priv key pair is generated, the pub/priv key of the CID is used when the authenticity of the chip is checked by means of a challenge response scheme. Everything happens in the client app (2021: iOS or Android; and the client code is open source), where there is no communication with Tangem, so Tangem is not able to see any activity conducted by this CID in an authenticity check. The CID and corresponding key pairs are not used in any other interaction. A new wallet with new pub/private key pair is generated on chip, with these keys being used for any transactions, signing, etc.
Q: With the chip firmware being proprietary, how can we be sure that the newly generated private keys for new wallets are not still linked somehow to the cards CID? A: The firmware is audited by Kudelski and can be verified with a published hash. TBD: How can it be verified, when and by whom? If the firmware is not open source, then somebody has to draw a hash from it in an authorized situation. However, Tangem cards are EAL6+ and FIDO2 certified.
On the issue of Rotation: | TBW prio 2 |
**Q: DHTs are not an immutable linear chronology oracle, which is the heart of the actual security problem. You claim KERI solves the security problem with DHTs?
The immutable linear chronology is provided by the key event log (KEL) data structure itself. Getting a full copy is all you need. When retrieving a KEL over a network, then as you say a witness can prune some amount of the latest events, but every witness would have to be compromised for that to be undetectable.
If parties are so concerned, they could establish a large collectivized set of witnesses that sign and distribute all key events presented to this network (this would essentially be a Proof of Authority/federated blockchain but would require (configurable)% compromise for undetectable pruning of recent history. Only PoA/federated because the witness sets are designated by the controllers, so you could not just use arbitrary witnesses who join and leave the network at leisure (afaik).
The difference between the chain and the DHT is that not all DHT nodes act as witnesses for all KELs in the system (in the sense that they don't provide receipts for every KEL and aren't referenced in the witness sets of every KEL), but they could all (or at least the ones holding the KEL you seek) still provide availability for KELs and thus would have to all be compromised in order to hide a recent-history-pruning, only one has to transmit the new/complete version to prove all the other versions as being old/incomplete.
(CharlesCunningham)
The point of KERI is to encapsulate all the guarantees within KELs nothing else is needed. DHT is just for resolution process to find a place from where I can get it. This place can change as you like I could even get it in p2p interaction from someone else. DHT seems to be the most reasonable way to build solid infrastructure for resolution process but none of the nodes can actually inject or tamper KELs so you don't have to trust them or get any guarantees from them. Since if the node will miss behave it is very easy to detect that.
(RobertMitwicki)
**Q: You are arguing KERI affords greater security than a decentralized linear event system like Bitcoin?
...you would be fundamentally arguing that you can record a singular, immutable linear event history more securely than Bitcoin, and I see nothing in KERI that would indicate that.
Read the answer to this first.
If you read Szabo's paper on threshold structures, you get security of the same type when ever you use a threshold structure, be it MFA, Multi-Sig, or Distributed consensus. They all are using a combination of multiple relatively weak attack surfaces that must be simultaneously compromised for a successful attack. So multiplying simultaneous weak surfaces = functional equivalent of a stronger attack surface. So when you look at KERI you see that the security is primarily due to cryptographic strength and the witnesses are not the primary source of security but merely secure one thing, that is the availability of the KEL for an identifier. Not the KEL itself. The KEL itself is secured by signatures.
From a Validator perspective their security is due to duplicity detection. Successful attack against duplicity detection requires an eclipse attack. Ledgers such as bitcoin are also susceptible to eclipse attacks. So in an apples to apples (resistance to eclipse attack) a KERI watcher network of comparable reach (1000's of watchers) would have comparable resistance to an eclipse attack.
***Q: Differences between blockchain-based security and KERI security
- Where KERI doesn't need total ordering in its logs, blockchain do need that. What KERI needs is watchers that construct string of event in the relative order of reception of the KEL | TBW please explain or improve this: what is this, why is it important? |
- Another characteristic is that KERI identifiers are transferable and blockchain-based identifiers are not, they are bound to their ledger.
***Q: How does FIFO prevent effective DOS attacks in Out-of-order KAACE?
An escrow cache of unverified out-of-order event provides an opportunity for malicious attackers to send forged event that may fill up the cache as a type of denial of service attack. For this reason escrow caches are typically FIFO (first-in-first-out) where older events are flushed to make room for newer events. [Paragraph 11.3.1] (in KERI WP)
Question: how does FIFO prevent effective DOS attacks?
By load-balancing the incoming messages. If you don't have any load-balancing, the messages are going to be processed First In First Out. Only when an attacker has full bandwidth available to overload the buffer, they could frustrate the process to get honest messages in. As soon as you’re able to balance the receipt of messages in the buffer, you’ll be able to get the right messages (from honest senders) through. (@henkvancann)
***Q: I don’t feel KERI is capable of delivering on all the promises made. It’s trivial to have a witness strategy that fails to meet those promises
*Which is not true for bitcoin. Nobody gets to alter the witness strategy of bitcoin without a HUGE amount of demonstrable proof, politicking, and advocacy. Most of my problems with innovative DLTs or other distributed systems are that I struggle to internalize how they actually guarantee anything*
If you are very familiar with PoW and therefore Bitcoin and Ethereum but not non-PoW Byzantine Agreement (BA), that where the cutting edge is for understanding the security model of KERI.
Non-PoW Byzantine Agreement (BA) and therefore KAACE on KERI witnesses which are a simplified variant of BA and under the hood look nothing like proof of work. Actually KERI with witnesses and KAACE looks the most like Stellar an open permission-less Byzantine Agreement algorithm. If these concepts are unfamiliar to you, yu might as a result have no intuition about why KERI could work because you then have little familiarity with distributed consensus mechanisms that provide PoW like guarantees, but are not PoW.
Actually BA came years before PoW so its the other way around (PoW provides BA like guarantees) but thats a quibble. So anyone trying to grasp how KERI security is guaranteed should first learn how non-PoW BA works before he/she could begin to believe why KERI could even work at all. Once you see this, then the dominos will start to fall.
***Q: The guarantees stated about KERI are inappropriate without a particular witness structure?
...and then you have to evaluate the witness strategy, which means KERI on its own doesn’t have the guarantees that the KERI creator keeps claiming.
A KERI witness structure never needs to provide total ordering (where total ordering is precisely defined in the literature for distributed consensus algorithms as providing one ordering for the union of transactions from multiple sets of transactions from multiple sets of clients where each set of transactions is ordered independently by each client that generates it. I.e. all the transactions from all the clients are combined into one set with one ordering = one total ordering. Most people can't define this correctly whenever asked.
Byzantine fault tolerant total ordering is the hard problem of distributed consensus. Safe agreement which is all that KERI provides is much much simpler. So almost any witness structure is much simpler and will still work good enough. And its not the witness structure alone but the witness and watcher structure:
- Witness for controllers
- Watchers for validators
Both are simpler consensus mechanisms compared to DLT algorithms. Distributed consensus describes a family of algorithms of which BFT Total Ordering distributed consensus is a subset. Pretty much all cloud databases that have redundant copies use some form of distributed consensus for synchronizing the copies of the database. They all use some form of authentication for securing that consensus but they are not in any real sense of the term using Byzantine Fault tolerant total ordering distributed consensus. Setting up witness pools and watcher pools in KERI is of comparable complexity to spinning up a redundant Postgres or CouchDB cluster. So KERI's guarantees come from nothing much more complicated than that. Nobody thinks that a CouchDB cluster is too complex to understand but few actually know the algorithmic details of its low level of distributed consensus.
(SamMSmith)
***Q: How can I bind external key material to AIDs in KERI?
How can I bind external key material to AIDs, such that the AID retains its own key, but picks up an association to an additional key that has meaning elsewhere?
In ascending degree of security:
- BADA policy, you don't anchor to a KEL. It's a date-time stamp together with the keystate
- Put a seal in your KEL. You can do this by creating an interaction event with the KLI.
- Add a TEL for the key material and thus add additional security