Create a search index
Instructions plus background.
Instructions: how to add a website to the search index
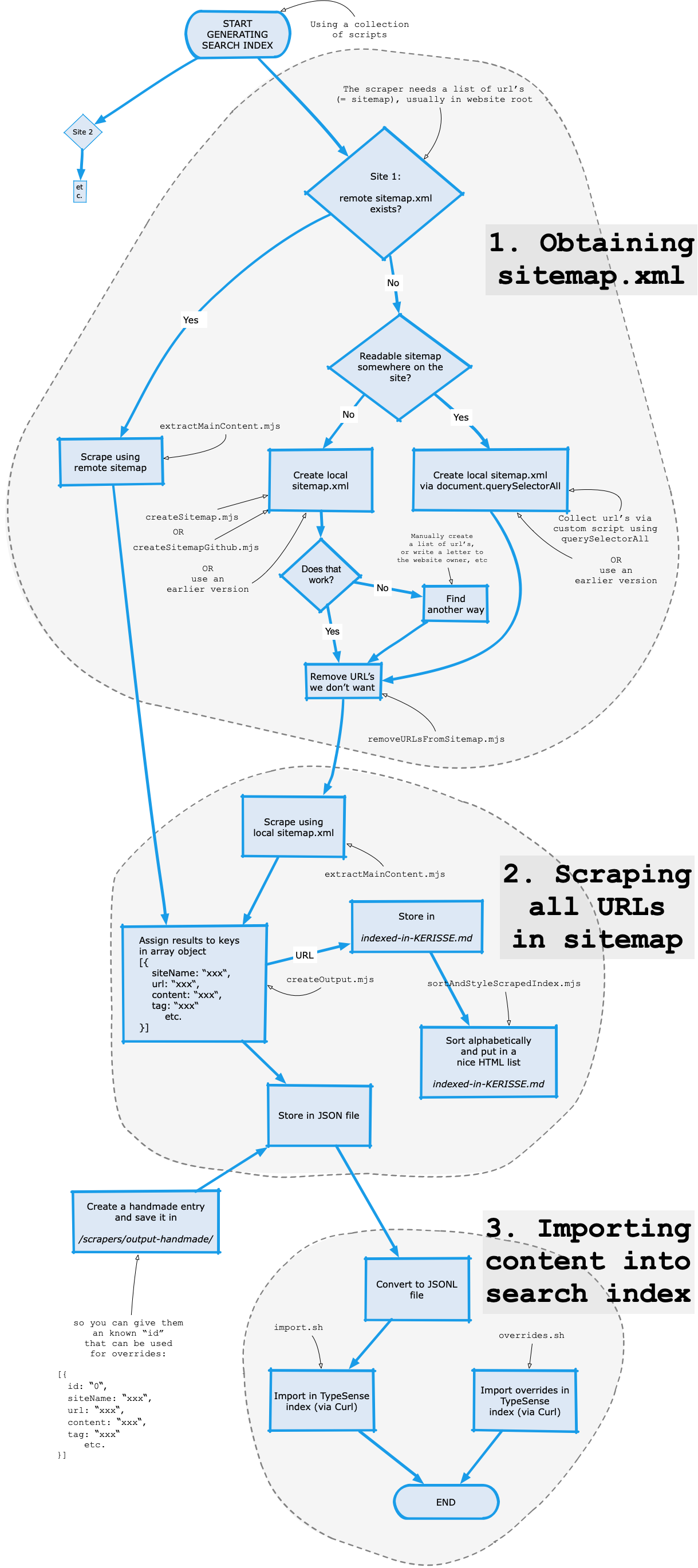
To add a website to the search index there are three parts to consider:
- Obtaining a sitemap.xml
- Scraping all the URLs in the sitemap
- Importing the content into the search index
Everything is done via the terminal (command line).
Sitemap
Find out if the website has a sitemap.xml.
If the website is https://the-website.com then try https://the-website.com/sitemap.xml, if that gives a list with URLs then that is your sitemap. Write it down so you can use it in a moment.
If it does not exist, or you think it is not up to date then make a sitemap via de Kerisse sitemap creator:
Open search-index-typesense/config/config_sitemaps_create.sh and follow the instructions.
There are two sections General websites and Github repos. Use sitemap-generator for a website in general and use the specialized createSitemapGithub.mjs for Github repo's.
Scraper
Now that we have the URLs that we want to scrape, we have to configure the scraper.
Open search-index-typesense/config/configScraperGenericSitemaps.mjs.
For every website there is a config object and a function. Every function has to be exported. This is not very user-friendly, and will change in the future.
Now go to the main menu:
sh search-index-typesense/main.sh
Choose option [1] Scrape all sites
It can take a long time before the scraper finishes. The terminal will output what is happening.
Import
After the scrape session has finished, go to the main menu again:
sh search-index-typesense/main.sh
and choose option [3] Import
Now the new content will be imported into the Typesense system (in the cloud).
Additional config options
Go to the config section: search-index-typesense/config/
For manual entries in the search index, see this Readme
For manual created sitemaps, see this Readme
For manual created sitemaps, see this Readme
It is possible to override search index entries and give them prio in the search results.
Example:
[
{
"name": "Diger",
"query": "Diger",
"url": "https://github.com/WebOfTrust/keripy/blob/main/src/keri/core/coring.py",
"position": 1,
"match": "exact"
}
]
Background info
For who is this how-we-did: Maintainers of the KERISSE site
Why should you stick to this step by step: | @kordwarshuis ?? |
Three steps
The creation of a search index for a website involves three steps:
- Decide which webpages (URLs) we want in our search index
- Retrieve the content of the URLs (scraping)
- Import the content into the Typesense search index
1: Decide which webpages (URLs) we want in our search index
You cannot be sent out to fetch something if they don't tell you where to go. That is what a sitemap is for.
We have to create lists that contain all URLs that should be visited and scraped. These lists are called sitemaps.
A sitemap is a list of URLs. The most common format is XML.
There are three kinds of sitemaps we have to deal with:
- The sitemap.xml can be remote, that means, it is located at the domain that you will scrape, usually in the root, named “sitemap.xml”. It is also a source for search engines like Google and Bing. If this is not present, we have to look further:
- The remote sitemap can also be in the form of an HTML sitemap. This sitemap is meant for human visitors but can also be read by scrapers. If this also does not exist, we have to create something ourselves:
- The sitemap can be a local sitemap. Meaning: this sitemap is created by you, using a sitemap builder or manually.
2: Retrieve the content of the URLs (scraping)
The scraper uses the sitemaps as input and goes through all the URLs and indexes all paragraphs, lists, tables, code fragments, and saves it in JSONL (a special form of JSON) format.
3: Import the content into the Typesense search index
When all the URLs of a website (or multiple websites) have been scraped and captured in JSON, this JSON is imported into the search engine. The search engine we use is called Typesense, and the data is imported into their cloud solution.
In Typesense a “document” is what a “record” is in a database.
The documents we want to import have to follow a schema (Example schema on the Typesense website). We created our own schema for Kerisse.
More info on the Typesense website.
More detailed steps
- Test If Required Libraries Are Installed
- Initializing
- Get the directory where the main.sh script is located
- Preparing
- Prepare file system. Remove old files and directories and create new ones.
- Copy handmade stuff: entries for direct import into Typesense, manual files, sitemaps.
- Create sitemaps via sitemap-generator.
- Remove unwanted urls from the sitemaps (new sitemaps generated or not)
- Filenames to lowercase.
- Fetch external content from Google Sheets.
- Start Scraping
- Scrape the websites.
- Split the content.jsonl file into multiple files so the size is optimal for Typesense.
- Count the total number of lines in all .jsonl files and write it to log dir.
- Sort and style the index file.
- Backing Up
- Backup output (scrape results, handmade stuff, sitemaps, logs, webpage overview, typesense export).
Software used
The following tools are used for scraping:
- Cheerio
- Puppeteer
Visualisation